ES学习二:Lucene的segment
什么是LSM
LSM是当前被用在许多产品的文件结构策略:HBase, Cassandra, LevelDB, SQLite,甚至在mangodb3.0中也带了一个可选的LSM引擎(Wired Tiger 实现的)。
简单的说,LSM被设计来提供比传统的B+树或者ISAM更好的写操作吞吐量,通过消去随机的本地更新操作来达到这个目标。
那么为什么这是一个好的方法呢?这个问题的本质还是磁盘随机操作慢,顺序读写快的老问题。这二种操作存在巨大的差距,无论是磁盘还是SSD。

上图很好的说明了这一点,他们展现了一些反直觉的事实,顺序读写磁盘(不管是SATA还是SSD)快于随机读写主存,而且快至少三个数量级。这说明我们要避免随机读写,最好设计成顺序读写。
所以,让我们想想,如果我们对写操作的吞吐量敏感,我们最好怎么做?一个好的办法是简单的将数据添加到文件。这个策略经常被使用在日志或者堆文件,因为他们是完全顺序的,所以可以提供非常好的写操作性能,大约等于磁盘的 理论速度 ,也就是200~300 MB/s。
因为简单和高效,基于日志的策略在大数据之间越来越流行,同时他们也有一些缺点,从日志文件中读一些数据将会比写操作需要更多的时间,需要倒序扫描,直接找到所需的内容。
这说明日志仅仅适用于一些简单的场景:1. 数据是被整体访问,像大部分数据库的WAL(write-ahead log) 2. 知道明确的offset,比如在Kafka中。
所以,我们需要更多的日志来为更复杂的读场景(比如按key或者range)提供高效的性能,这儿有4个方法可以完成这个,它们分别是:
- 二分查找: 将文件数据有序保存,使用二分查找来完成特定key的查找。
- 哈希:用哈希将数据分割为不同的bucket
- B+树:使用B+树 或者 ISAM 等方法,可以减少外部文件的读取
- 外部文件: 将数据保存为日志,并创建一个hash或者查找树映射相应的文件。
所有的方法都可以有效的提高了读操作的性能(最少提供了O(log(n)) ),但是,却丢失了日志文件超好的写性能。上面这些方法,都强加了总体的结构信息在数据上,数据被按照特定的方式放置,所以可以很快的找到特定的数据,但是却对写操作不友善,让写操作性能下降。
更糟糕的是,当我们需要更新hash或者B+树的结构时,需要同时更新文件系统中特定的部分,这就是上面说的比较慢的随机读写操作。 这种随机的操作要尽量减少 。
所以这就是 LSM 被发明的原理, LSM 使用一种不同于上述四种的方法,保持了日志文件写性能,以及微小的读操作性能损失。本质上就是让所有的操作顺序化,而不是像散弹枪一样随机读写。
LSM树的核心思想
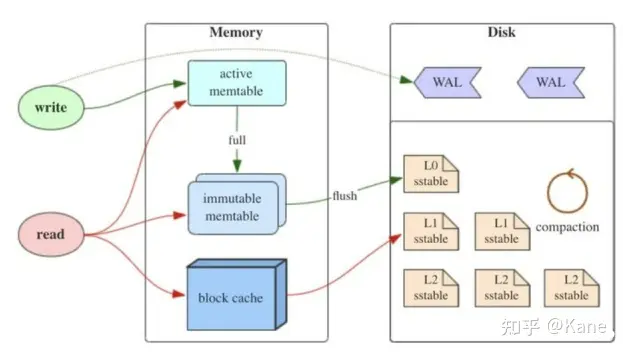
如上图所示,LSM树有以下三个重要组成部分:
1) MemTable
MemTable是在***内存***中的数据结构,用于保存最近更新的数据,会按照Key有序地组织这些数据,LSM树对于具体如何组织有序地组织数据并没有明确的数据结构定义,例如Hbase使跳跃表来保证内存中key的有序。
因为数据暂时保存在内存中,内存并不是可靠存储,如果断电会丢失数据,因此通常会通过WAL(Write-ahead logging,预写式日志)的方式来保证数据的可靠性。
2) Immutable MemTable
当 MemTable达到一定大小后,会转化成Immutable MemTable。Immutable MemTable是将转MemTable变为SSTable的一种中间状态。写操作由新的MemTable处理,在转存过程中不阻塞数据更新操作。
3) SSTable(Sorted String Table)
***有序键值对***集合,是LSM树组在***磁盘***中的数据结构。为了加快SSTable的读取,可以通过建立key的索引以及布隆过滤器来加快key的查找。

这里需要关注一个重点,LSM树(Log-Structured-Merge-Tree)正如它的名字一样,LSM树会将所有的数据插入、修改、删除等操作记录(注意是操作记录)保存在内存之中,当此类操作达到一定的数据量后,再批量地顺序写入到磁盘当中。这与B+树不同,B+树数据的更新会直接在原数据所在处修改对应的值,但是LSM数的数据更新是日志式的,当一条数据更新是直接append一条更新记录完成的。这样设计的目的就是为了顺序写,不断地将Immutable MemTable flush到持久化存储即可,而不用去修改之前的SSTable中的key,保证了顺序写。
因此当MemTable达到一定大小flush到持久化存储变成SSTable后,在不同的SSTable中,可能存在相同Key的记录,当然最新的那条记录才是准确的。这样设计的虽然大大提高了写性能,但同时也会带来一些问题:
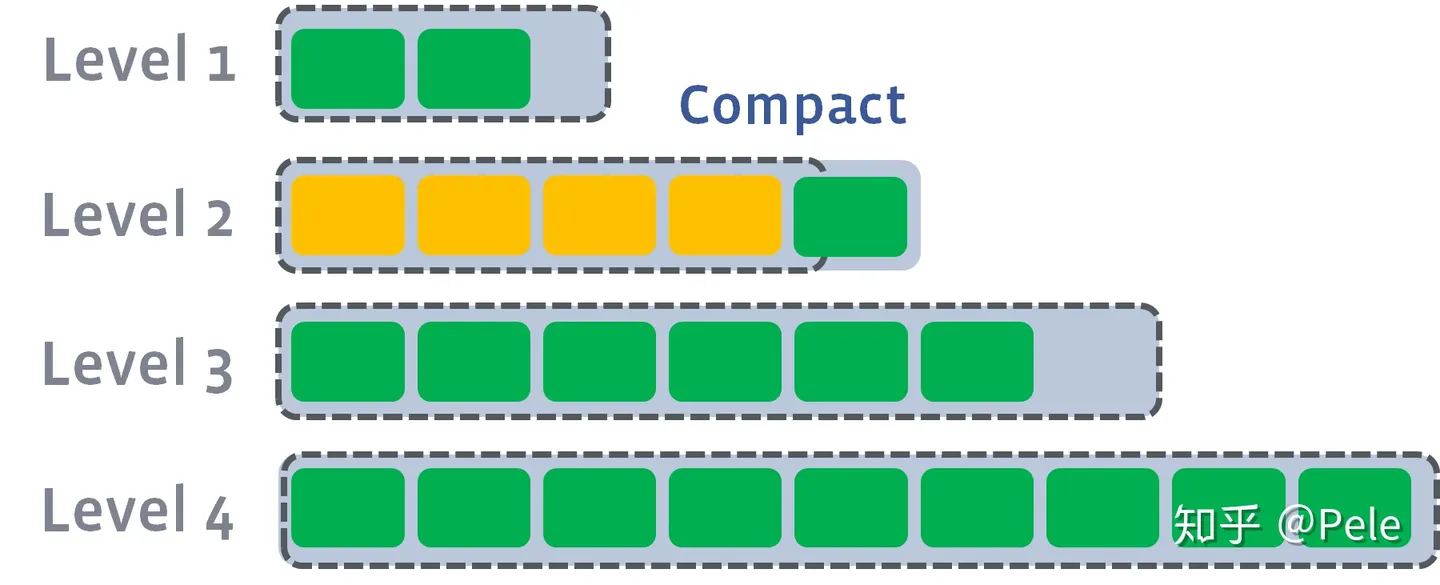
1)冗余存储,对于某个key,实际上除了最新的那条记录外,其他的记录都是冗余无用的,但是仍然占用了存储空间。因此需要进行Compact操作(合并多个SSTable)来清除冗余的记录。
2)读取时需要从最新的倒着查询,直到找到某个key的记录。最坏情况需要查询完所有的SSTable,这里可以通过前面提到的索引/布隆过滤器来优化查找速度。
2、LSM树的Compact策略
从上面可以看出,Compact操作是十分关键的操作,否则SSTable数量会不断膨胀。在Compact策略上,主要介绍两种基本策略:size-tiered和leveled。
不过在介绍这两种策略之前,先介绍三个比较重要的概念,事实上不同的策略就是围绕这三个概念之间做出权衡和取舍。
1)读放大:读取数据时实际读取的数据量大于真正的数据量。例如在LSM树中需要先在MemTable查看当前key是否存在,不存在继续从SSTable中寻找。
2)写放大:写入数据时实际写入的数据量大于真正的数据量。例如在LSM树中写入时可能触发Compact操作,导致实际写入的数据量远大于该key的数据量。
3)空间放大:数据实际占用的磁盘空间比数据的真正大小更多。上面提到的冗余存储,对于一个key来说,只有最新的那条记录是有效的,而之前的记录都是可以被清理回收的。
1) size-tiered 策略

size-tiered策略保证每层SSTable的大小相近,同时限制每一层SSTable的数量。如上图,每层限制SSTable为N,当每层SSTable达到N后,则触发Compact操作合并这些SSTable,并将合并后的结果写入到下一层成为一个更大的sstable。
由此可以看出, 当层数达到一定数量时,最底层的单个SSTable的大小会变得非常大 。并且 size-tiered策略会导致空间放大比较严重 。即使对于同一层的SSTable,每个key的记录是可能存在多份的,只有当该层的SSTable执行compact操作才会消除这些key的冗余记录。
2) leveled策略

每一层的总大小固定,从上到下逐渐变大
leveled策略也是采用分层的思想,每一层限制总文件的大小。
但是跟size-tiered策略不同的是,leveled会将每一层切分成多个大小相近的SSTable。这些SSTable是这一层是全局有序的,意味着一个key在每一层至多只有1条记录,不存在冗余记录。之所以可以保证全局有序,是因为合并策略和size-tiered不同,接下来会详细提到。
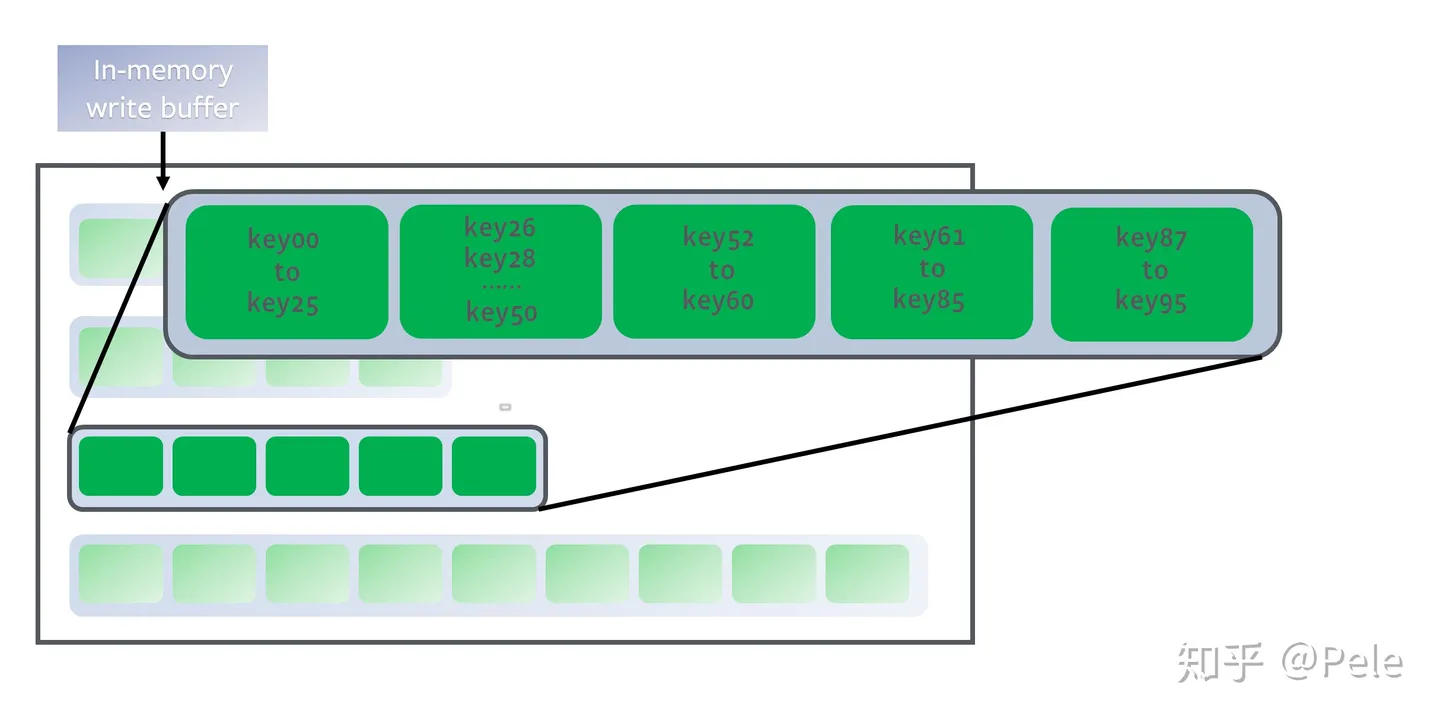
每一层的SSTable是全局有序的
假设存在以下这样的场景:
- L1的总大小超过L1本身大小限制:
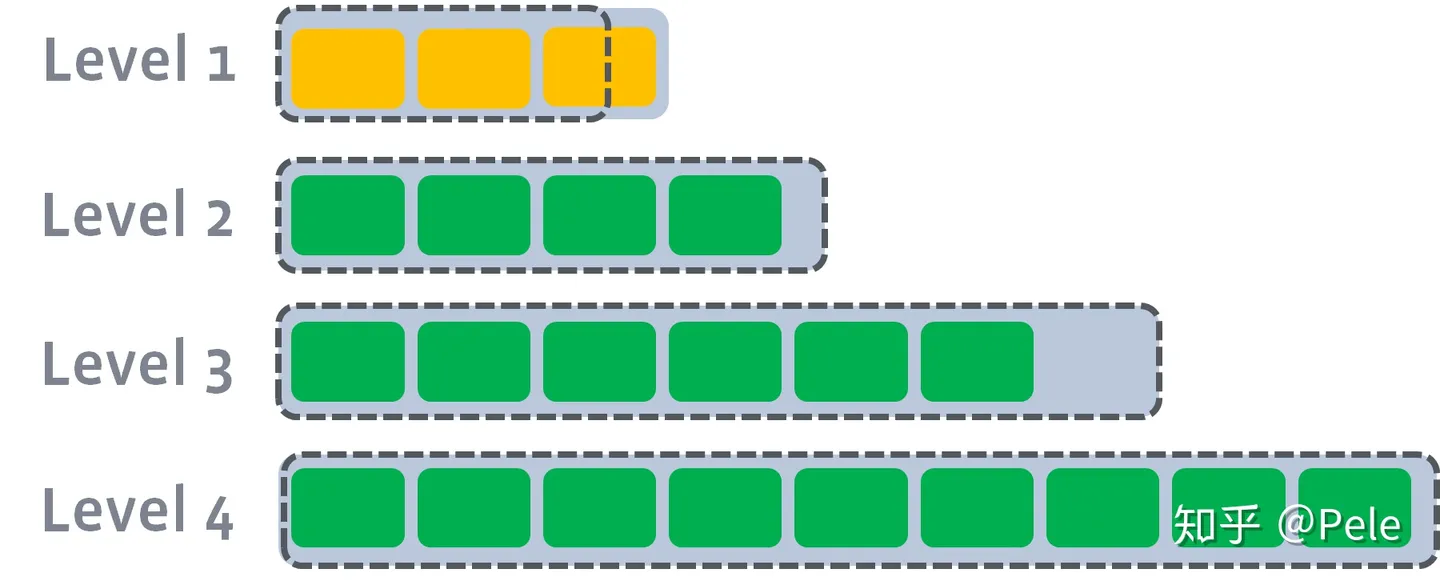
此时L1超过了最大阈值限制
- 此时会从L1中选择至少一个文件,然后把它跟L2 有交集的部分(非常关键) 进行合并。生成的文件会放在L2:
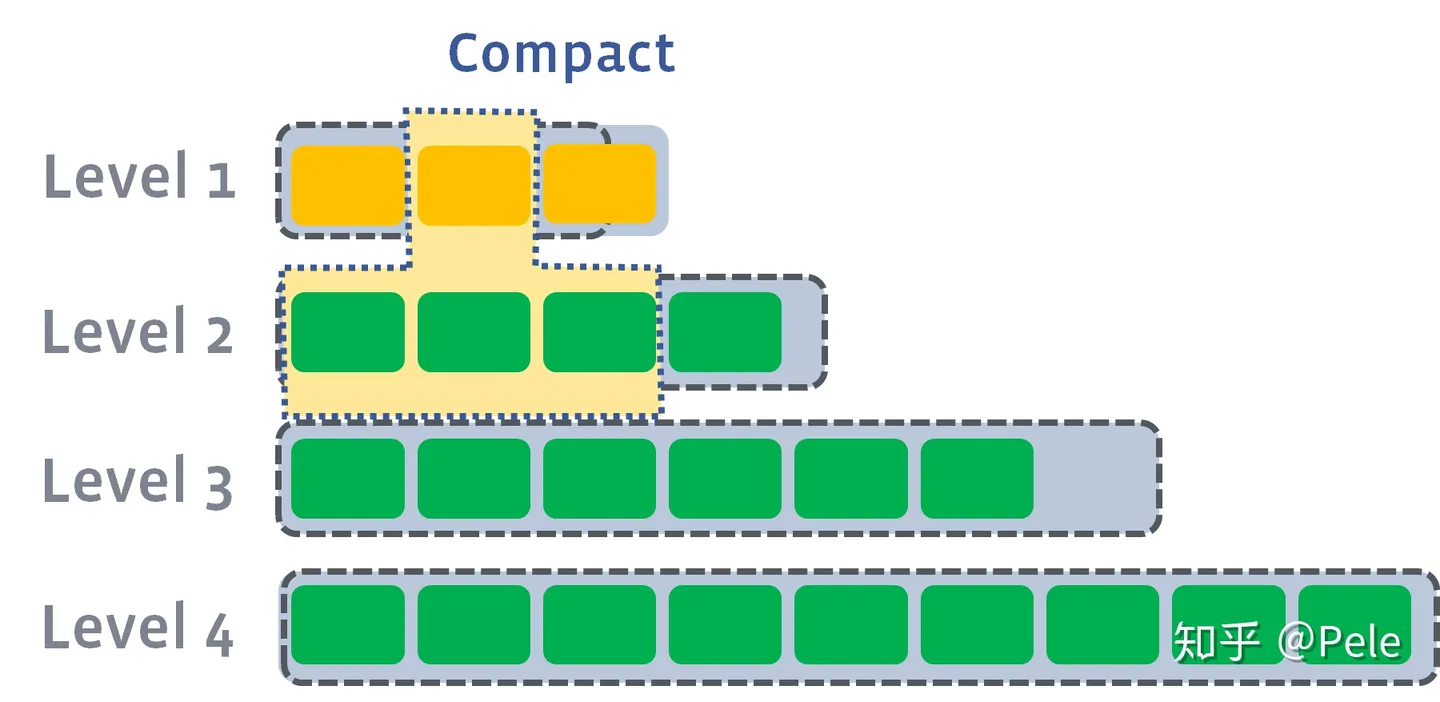
如上图所示,此时L1第二SSTable的key的范围覆盖了L2中前三个SSTable,那么就需要将L1中第二个SSTable与L2中前三个SSTable执行Compact操作。
- 如果L2合并后的结果仍旧超出L5的阈值大小,需要重复之前的操作 —— 选至少一个文件然后把它合并到下一层:
需要注意的是, 多个不相干的合并是可以并发进行的 :

leveled策略相较于size-tiered策略来说,每层内key是不会重复的,即使是最坏的情况,除开最底层外,其余层都是重复key,按照相邻层大小比例为10来算,冗余占比也很小。因此空间放大问题得到缓解。但是写放大问题会更加突出。举一个最坏场景,如果LevelN层某个SSTable的key的范围跨度非常大,覆盖了LevelN+1层所有key的范围,那么进行Compact时将涉及LevelN+1层的全部数据。
介绍完LSM,就开始讲lucene的Segment,它很大的借鉴了LSM的思想,并且在它基础上优化了很多。
什么是Segment
Lucene的一个Index会由一个或多个sub-index构成,sub-index被称为Segment,每个segment中包含多个documents文件,一个segment中会有完整的正向索引和反向索引。
在搜索时,Lucene会遍历这些segments,以segments为基本单位独立搜索每个segments文件,而后再把搜索结果合并。
而Segment设计思想,与LSM类似但又有些不同,继承了LSM(Log Structured Merge Trees)中数据写入的优点,但是在查询上只能提供近实时而非实时查询。Lucene中的数据写入会先写内存的一个Buffer(类似LSM的MemTable,但是不可读),当Buffer内数据到一定量后会被flush成一个Segment,每个Segment有自己独立的索引,可独立被查询,但数据永远不能被更改。
Index的查询需要对多个Segment进行查询并对结果进行合并,还需要处理被删除的文档,为了对查询进行优化,Lucene会有策略对多个Segment进行合并,这点与LSM对SSTable的Merge类似。
Segment在被flush或commit之前,数据保存在内存中,是不可被搜索的,这也就是为什么Lucene被称为提供近实时而非实时查询的原因。
Lucene为什么要加Segment概念
- 简化了写文档的逻辑,解耦了写文档和读文档。如果没有Segment在写文档的时候势必要修改整个索引,所以会影响到文档的读
- 提升了写文档的速度,由于只是创建包含单个文档的Segment,所以速度比较快,而且由于包含新写文档的段里的数据都是排序好的,所以在和已有段合并的时候速度也是比较快的
ElasticSearch的segment
我们知道Elasticsearch是一个near-realtime(近实时)的搜索引擎。这个近实时指的是数据添加到Elasticsearch后并不能马上被搜索到,而是要等待一定时间(默认为1秒)。
这里的原因是ElasticSearch底层依赖lucene来提供搜索能力,一个lucene index由许多独立的Segments组成。
Segment是最小的数据存储单元。其中包含了文档中的词汇字典、词汇字典的倒排索引以及Document的字段数据。 因此Segment直接提供了搜索功能 。 但是Segment能提供搜索的前提是数据必须被提交,即文档经过一系列的处理之后生成倒排索引等一系列数据。可以想见这个过程是比较耗时的。 因此Elasticsearch并不会每接收到一条数据就提交到一个Segment中,一方面是因为这样耗时太长,另一方面是这样会生成巨量的Segment,降低了IO性能。
Elasticsearch采取的机制是将数据添加到lucene,lucene内部会维护一个数据缓冲区,此时数据都是不可搜索的。每隔一段时间(默认为1秒),Elasticsearch会执行一次refresh操作:lucene中所有的缓存数据都被写入到一个新的Segment,清空缓存数据。此时数据就可以被搜索。当然,每次执行refresh操作都会生成一个新的Segment文件,这样一来Segment文件有大有小,相当碎片化。Elasticsearch内部会开启一个线程将小的Segment合并(Merge)成大的Segment,减少碎片化,降低文件打开数,提升IO性能。
不过这样也带来一个问题。数据写入缓冲区中,没有及时保存到磁盘中,一旦发生程序崩溃或者服务器宕机,数据就会发生丢失。为了保证可靠性,Elasticsearch引入了Translog(事务日志)。每次数据被添加或者删除,都要在Translog中添加一条记录。这样一旦发生崩溃,数据可以从Translog中恢复。
不过,不要以为数据被写到Translog中就已经被保存到磁盘了。一般情况下,对磁盘文件的write操作,更新的只是内存中的页缓存,而脏页面不会立即更新到磁盘中,而是由操作系统统一调度,如由专门的flusher内核线程在满足一定条件时(如一定时间间隔、内存中的脏页面达到一定比例)将脏页面同步到磁盘上。因此如果服务器在write之后、磁盘同步之前宕机,则数据会丢失。这时需要调用操作系统提供的fsync功能来确保文件所有已修改的内容被正确同步到磁盘上。
Elasticsearch提供了几个参数配置来控制Translog的同步:
index.translog.durability
该参数控制如何同步Translog数据。有两个选项:request(默认):每次请求(包括index、delete、update、bulk)都会执行fsync,将Translog的数据同步到磁盘中。async:异步提交Translog数据。和下面的index.translog.sync_interval参数配合使用,每隔sync_interval的时间将Translog数据提交到磁盘,这样一来性能会有所提升,但是在间隔时间内的数据就会有丢失的风险。
index.translog.sync_interval:该参数控制Translog的同步时间间隔。默认为5秒。index.translog.flush_threshold_size:该参数控制Translog的大小,默认为512MB。防止过大的Translog影响数据恢复所消耗的时间。一旦达到了这个大小就会触发flush操作,生成一个新的Translog。
原文链接https://zhuanlan.zhihu.com/p/444433592?utm_id=0
标题:ES学习二:Lucene的segment
作者:michael
地址:https://blog.junxworks.cn/articles/2024/02/01/1706774640920.html