Prompt Engineering 提示词工程研究指南:六、提示词编写技巧(中)
四、自一致性Self-Consistency
自一致性可能是更高级的提示工程技术之一。Wang等人(2022年)提出了自一致性技术,旨在“取代思维链提示中使用的贪婪解码方法”。其思想是通过少样本的思维链提示抽样出多条不同的推理路径,并使用生成的结果选择最一致的答案。这有助于提升在涉及算术和常识推理的任务中的思维链提示的性能。
让我们尝试以下算术推理的例子:
当我6岁时,我妹妹的年龄是我的一半。现在我70岁了,我妹妹多大了?

很明细,这是错误的!我们如何通过自一致性来改进这个问题呢?让我们尝试一下。我们将使用Wang等人2022年的少样本示例:
Q: 有一片树林里有15棵树。林务人员今天会在树林里种树。种完以后,总共会有21棵树。林务人员今天种了多少棵树?
A: 我们开始有15棵树。后来有21棵树。差值就是拿来种的树的数量。所以,他们肯定种了21 - 15 = 6棵树。答案是6。
Q: 如果停车场里已经有3辆车,并且又有2辆车来了,停车场里现在有多少辆车?
A: 停车场里已经有3辆车。又有2辆车来了。现在停车场里总共有3 + 2 = 5辆车。答案是5。
Q: Leah有32块巧克力,她姐姐有42块。如果他们吃了35块,他们总共还剩多少块?
A: Leah有32块巧克力,Leah的姐姐有42块。这意味着原来总共有32 + 42 = 74块巧克力。吃掉了35块。所以他们总共还剩74 - 35 = 39块巧克力。答案是39。
Q: Jason有20个棒棒糖。他给了Denny一些棒棒糖。现在Jason只剩下12个棒棒糖。Jason给了Denny多少个棒棒糖?
A: Jason有20个棒棒糖。现在只剩下12个,所以他肯定把剩下的给了Denny。他给了Denny的棒棒糖数量一定是20 - 12 = 8个。答案是8。
Q: Shawn有五个玩具。圣诞节时,他从爸爸妈妈那里得到了每人两个玩具。他现在总共有多少个玩具?
A: 他有5个玩具。他从妈妈那里得到了2个,所以接下来他有了5 + 2 = 7个玩具。然后他又从爸爸那里得到了2个,所以总共他有7 + 2 = 9个玩具。答案是9。
Q: 从周一到周四共有9台电脑。每天增加5台电脑。现在服务器房里有多少台电脑?
A: 从周一到周四共有4天。每天增加5台电脑。这意味着总共增加了4 * 5 = 20台电脑。一开始有9台电脑,所以现在总共有9 + 20 = 29台电脑。答案是29。
Q: Michael一开始有58个高尔夫球。星期二,他丢了23个高尔夫球。星期三,又丢了2个。到星期三结束时,他还剩多少个高尔夫球?
A: Michael一开始有58个球。星期二丢了23个,所以现在剩下58 - 23 = 35个球。星期三又丢了2个,所以现在剩下35 - 2 = 33个球。答案是33。
Q: Olivia有23美元。她买了五个面包圈,每个面包圈3美元。她还剩下多少钱?
A: 她买了5个面包圈,每个面包圈花费3 * 5 = 15美元。所以她还剩下23 - 15 = 8美元。答案是8。
当我6岁时,我妹妹的年龄是我的一半。现在我70岁了,我妹妹多大了?

计算出最终答案需要几个步骤,但最终结果是对的。
五、生成知识引导Generated Knowledge Prompting
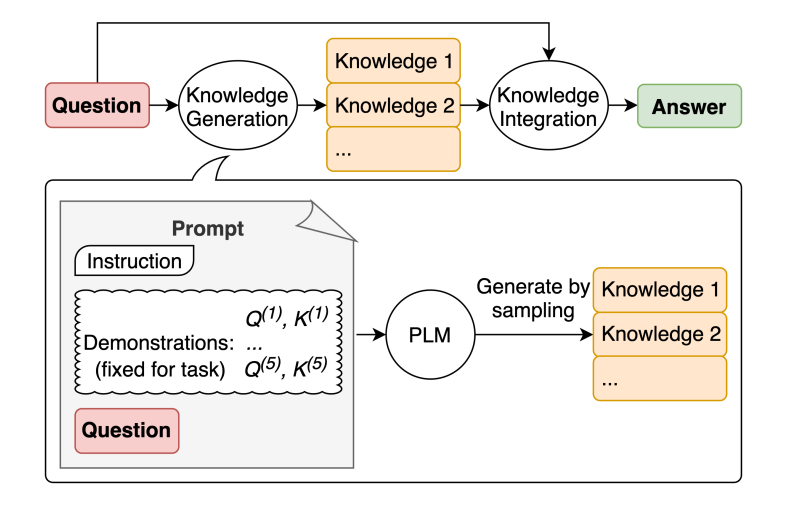
在不断改进的语言模型中,一种流行的技术是能够融合知识或信息,以帮助模型做出更准确的预测。
使用类似的思路,模型是否也能在进行预测之前生成知识呢?这正是刘等人在2022年的论文中尝试的内容 —— 生成知识作为提示的一部分。特别是对于常识推理等任务,这种方法对模型有多大的帮助呢?
让我们尝试一个简单的提示:
高尔夫比赛的一部分是试图获得比其他人更高的得分总数。是或否?
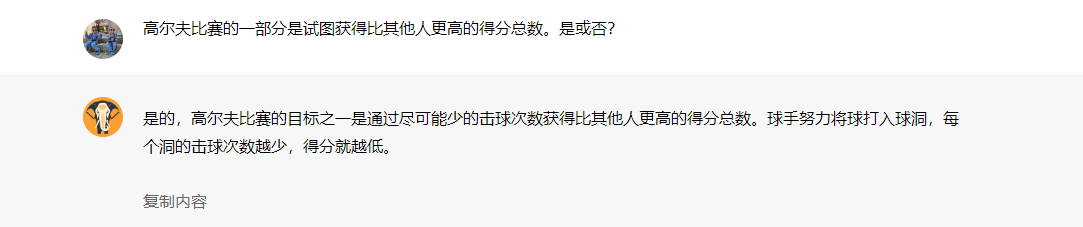
其实高尔夫应该是分数越低越好,这类错误暴露了语言模型在执行需要更多世界知识的任务时的局限性。我们如何通过知识生成来改进这一点呢?
首先,我们生成一些“知识”:
输入: 希腊的面积大于墨西哥。
知识: 希腊的面积约为131,957平方公里,而墨西哥的面积约为1,964,375平方公里,墨西哥比希腊大约1,389%。
输入: 眼镜总是会起雾。
知识: 当你的汗水、呼吸和周围空气中的水汽落在冷凝到镜片上时,会产生凝结物。水汽被冷却后会转化为微小的液滴,形成
一层你看到的雾。
输入: 鱼有自我思考的能力。
知识: 鱼比它们看起来更聪明。在许多方面,比如记忆力,它们的认知能力与非人类灵长类动物等“更高级”的脊椎动物相当甚
至超过。鱼的长期记忆帮助它们跟踪复杂的社会关系。
输入: 在一生中吸烟很多香烟的一个常见影响是患肺癌的风险高于正常水平。
知识: 那些一生中平均每天吸烟不到一支的人,肺癌死亡风险是绝对不吸烟者的9倍。在每天吸烟1到10支香烟之间的人群
中,患肺癌的风险几乎是绝对不吸烟者的12倍。
输入: 一块石头与一颗鹅卵石的大小相同。
知识: 鹅卵石是根据乌登-温特沃思沉积学尺度,具有4至64毫米颗粒大小的岩石碎屑。鹅卵石通常被认为比细颗粒(2至4毫
米直径)大,而比圆石(64至256毫米直径)小。
输入: 高尔夫的一部分是试图获得比其他人更高的得分总数。
知识:
知识一:
高尔夫的目标是以最少的杆数打完一组洞。高尔夫一般包括18个洞。每个洞在标准高尔夫球场上打一次。每一杆都算作一个分
数,总杆数用来确定比赛的胜者。
知识二:
高尔夫是一项以球杆和球为工具的精准运动,参赛选手(或高尔夫球手)使用多种类型的球杆,用尽可能少的杆数将球打入球
场上一系列的洞中。目标是以最低的击球数完成整个球场,计算方法是将每个洞的击球数相加得出总分。得分最低的球手获
胜。
我们使用了刘等人2022年论文中提供的提示词。
下一步是整合知识并进行预测。我将问题重新格式化为QA格式以引导回答的格式。
回答一
知识:高尔夫的目标是以最少的杆数打完一组洞。每一轮高尔夫比赛通常包括18个洞。每个洞在标准高尔夫球场上打一次。每一杆都计为一个分数,总杆数用来确定比赛的胜者。解释和回答:高尔夫的一部分是试图获得比其他人更高的分数,是或不是?
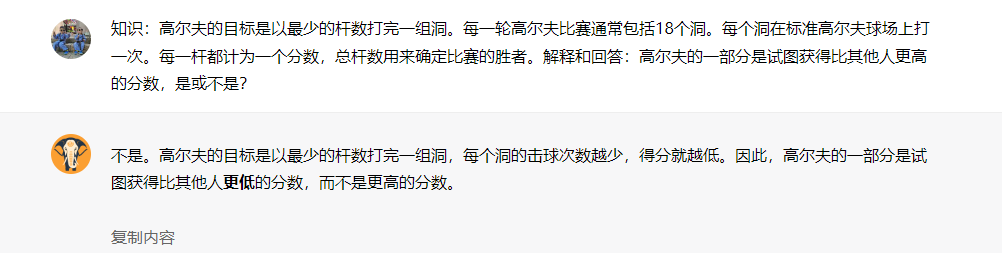
回答二
问题:高尔夫的一部分是试图获得比其他人更高的分数,是或不是?知识:高尔夫是一项精准的球杆运动,竞争的参赛选手(或高尔夫球手)使用多种类型的球杆,以最少的杆数将球打入球场上的一系列洞口。目标是以最低的分数完成球场,该分数是通过将每个洞上所用杆数相加计算得出的。分数最低的选手获得比赛的胜利。请解释和回答:

这个例子中发生了一些非常有趣的事情。在第一个回答中,模型非常自信,回答简短而且精准,但在第二个回答中不太自信,解释了很多规则。为了演示的目的,我简化了处理过程,但在得出最终答案时还有一些细节需要考虑。请参阅论文以获取更多信息。
六、思维树Tree of Thoughts (ToT)
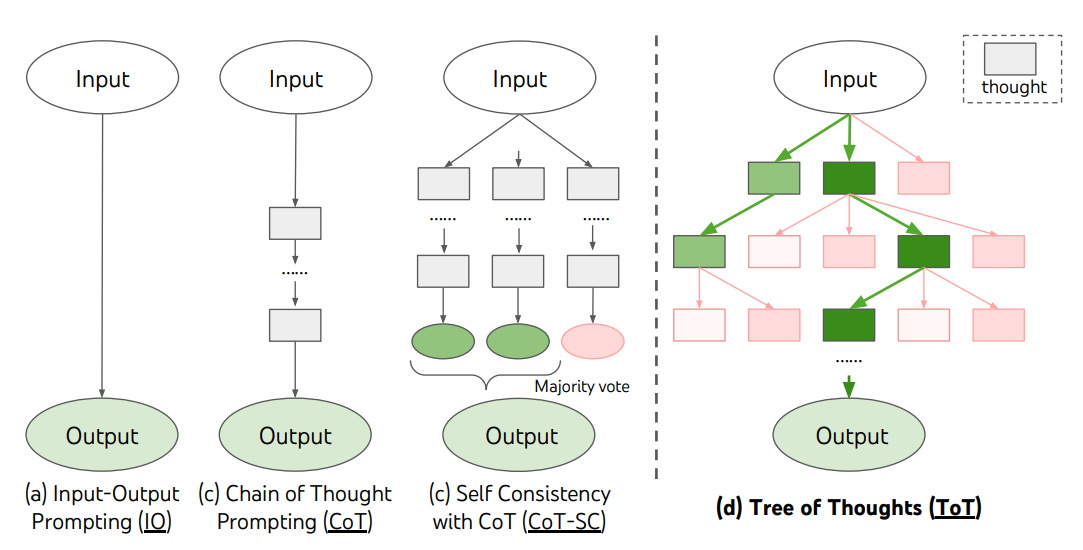
对于需要探索或战略前瞻的复杂任务,传统或简单的提示技术往往无法满足要求。Yao等人(2023)和Long(2023)最近提出了"Tree of Thoughts" (思维之树,ToT)的框架,它是一个概括了思维链提示的模型,并鼓励在思维过程中进行探索,这些思维作为解决语言模型中的一般性问题的中间步骤。
ToT维护着一个思维之树,其中的思维代表着一系列连贯的语言序列,作为解决问题的中间步骤。这种方法通过一个审慎的推理过程,让语言模型自我评估中间思维在解决问题上的进展。语言模型生成和评估思维的能力与搜索算法(如广度优先搜索和深度优先搜索)相结合,以实现对思维的系统探索,包括前瞻和回溯。
ToT框架的示意图如下:
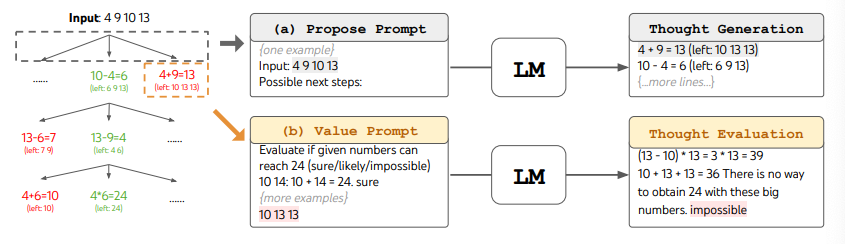
使用ToT时,不同的任务需要定义候选人数和思维/步骤数。例如,如论文中所示,"Game of 24"被用作数学推理任务,需要将思维分解为3个步骤,每个步骤涉及一个中间方程。在每个步骤中,保留最佳b=5个候选人。
要在ToT中执行"Game of 24"任务的BFS,语言模型被提示对每个思维候选人进行评估,判断其是否能达到24,评估结果为"sure/maybe/impossible"。正如作者所述,"目标是促进能够在少数前瞻试验中得出判断的正确部分解,并基于"太大/太小"的常识判断排除不可能的部分解,并保留其余部分为"maybe""。每个思维的值被采样3次。过程示意图如下:
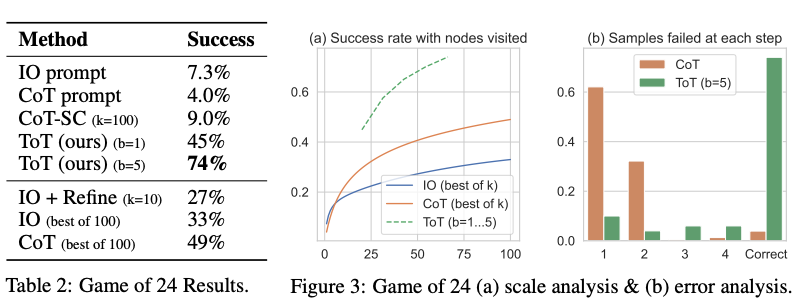
从下面的图表中报告的结果来看,ToT明显优于其他提示方法:
在高层次上,姚等人(2023)和龙(2023)的主要想法是相似的。两者通过多轮对话的方式,通过树搜索增强LLM(语言模型)在复杂问题解决上的能力。其中一个主要区别是,姚等人(2023)采用了DFS/BFS/beam search,而龙(2023)提出的树搜索策略(即何时回溯和回溯多少层等)是由经过强化学习训练的"ToT Controller"驱动的。DFS/BFS/beam search是通用的问题解决策略,没有适应特定问题的调整。相比之下,通过强化学习训练的ToT Controller可以从新的数据集或通过自我对弈(AlphaGo与 brute force search)中学习,因此基于强化学习的ToT系统即使在固定的LLM的情况下,仍然可以不断发展和学习新知识。
Hulbert(2023)提出了Tree-of-Thought Prompting,将ToT框架的主要概念作为一种简单的提示技术,通过单个提示使LLM评估中间思想。一个样例的ToT提示是:
假设有三位不同的专家在回答这个问题。所有专家将记录下他们思考的一个步骤,然后与团队分享。然后所有专家将继续进行
下一步,以此类推。如果任何一位专家意识到自己在任何一点上是错误的,则离开。这个问题是...
七、检索增强生成Retrieval Augmented Generation (RAG)
通用语言模型可以进行微调,以实现一些常见任务,例如情感分析和命名实体识别。这些任务通常不需要额外的背景知识。
对于更复杂和知识密集型的任务,可以构建基于语言模型的系统,以访问外部知识源来完成任务。这可以提高生成的响应的事实一致性和可靠性,并有助于缓解“幻觉”问题。
元AI研究人员提出了一种称为“检索增强生成”(RAG)的方法来解决这些知识密集型的任务。RAG将信息检索组件与文本生成模型相结合。RAG可以进行微调,并且其内部知识可以高效地进行修改,而无需重新训练整个模型。
RAG接收输入并在给定源(例如维基百科)的情况下检索一组相关/支持的文档。这些文档将与原始输入提示连接在一起,并馈入文本生成器生成最终的输出。这使得RAG适应了事实可能随时间变化的情况。这对于LLM的参数化知识是固定的情况非常有用。RAG允许语言模型绕过重新训练,通过基于检索的生成方式访问最新的信息,从而生成可靠的输出。
Lewis等人提出了用于RAG的通用微调方法。预训练的序列到序列模型被用作参数化记忆,而维基百科的密集向量索引被用作非参数化记忆(通过神经预训练的检索器进行访问)。下面是这种方法的概述:
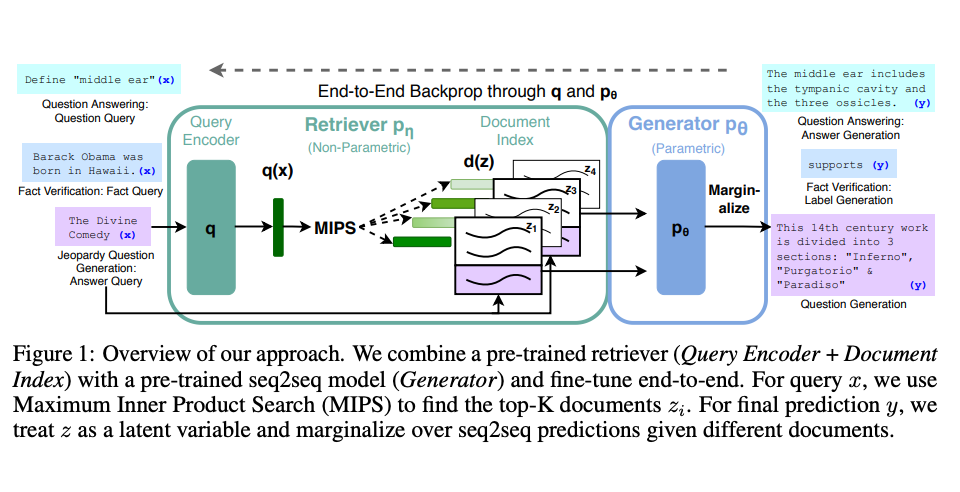
RAG在几个基准测试中表现出色,例如自然问题、网络问题和精心策划的Trec问题。在对MS-MARCO和Jeopardy问题进行测试时,RAG生成的响应更加事实、具体和多样化。RAG还改善了FEVER事实验证的结果。
这显示了RAG在知识密集型任务中增强语言模型输出的潜力。
最近,这些基于检索的方法变得越来越受欢迎,并与ChatGPT等流行的LLM结合使用,以提高能力和事实的一致性。
PS:本文ChatGPT对话由灵象智问AI提供,官网https://www.lxzw888.com/
标题:Prompt Engineering 提示词工程研究指南:六、提示词编写技巧(中)
作者:michael
地址:https://blog.junxworks.cn/articles/2023/07/19/1689762860574.html