Prompt Engineering 提示词工程研究指南:五、提示词编写技巧(上)
一、零样本提示词Zero-Shot
大型的LLM(语言模型),比如GPT-3,经过调整可以遵循指令,并且它们经过大量的数据训练,所以它们可以执行一些“零样本”任务。
在前一部分中,我们尝试了一些“零样本”示例,这是其中之一:
将文本分类为中性、负面或正面。
文本:我觉得这个假期还可以。
情感:
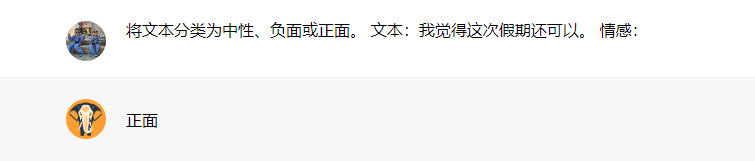
请注意,在上述提示中,我们没有为模型提供任何文本示例及其分类,LLM已经理解了“情感”——这就是零样本学习的能力。研究发现,指导调整可以改善零样本学习。指导调整本质上是指在通过指令描述的数据集上对模型进行微调的概念。此外,通过从人类反馈中进行强化学习(RLHF)已经被采用来扩展指导调整,使模型更好地符合人类的偏好。这一最新发展推动了ChatGPT等模型的性能。我们将在接下来的章节中讨论所有这些方法和途径。
当零样本学习无法奏效时,建议在提示中提供示范或示例,以实现少样本提示。
二、少样本提示词Few-Shot
虽然大型语言模型展示了令人瞩目的零样本能力,但在使用零样本设置时,它们在更复杂的任务上仍然存在局限性。少样本提示可以作为一种技术,用于在上下文中进行学习,我们在提示中提供示范来引导模型获得更好的性能。这些示范作为后续示例的条件,我们希望模型能够生成响应。让我们通过一个在Brown等人的文章中提到的例子来演示少样本提示。在这个例子中,任务是在句子中正确使用一个新单词。
一个"whatpu"是一种生长在坦桑尼亚的小型毛茸动物。一个使用了"whatpu"一词的句子例子是:
我们在非洲旅行时看到了这些非常可爱的whatpu。
做一个"farduddle"意味着迅速跳上跳下。一个使用了"farduddle"一词的句子例子是:

我们可以观察到模型通过只提供一个示例(即1-shot)已经学会了执行任务的方式。对于更困难的任务,我们可以尝试增加示范的数量(例如3-shot、5-shot、10-shot等)进行实验。
根据Min等人的研究发现,以下是一些关于少样本演示/示范的更多提示:
- 标签空间和示范中指定的输入文本分布都很重要(无论单个输入的标签是否正确)
- 使用的格式对性能也起着关键作用,即使只是使用随机标签,这比没有标签要好得多。
- 额外的结果显示,从真实标签分布中选择随机标签(而不是均匀分布)也有助于提升性能。
让我们尝试一些示例。让我们首先尝试一个使用随机标签的例子(意味着将标签Negative和Positive随机分配给输入):
这太棒了!// 负面
这太糟糕了!// 正面
哇,那部电影太棒了!// 正面
多么可怕的节目!//

尽管标签被随机化了,我们仍然得到了正确的答案。请注意,我们还保持了格式,这也有所帮助。事实上,通过进一步的实验,我们发现我们正在进行实验的新GPT模型对于即使是随机格式也变得更加稳健。例如:
正面 这太棒了! 这太糟糕了!负面 哇,那部电影太棒了! 负面 这场演出太糟糕了!--
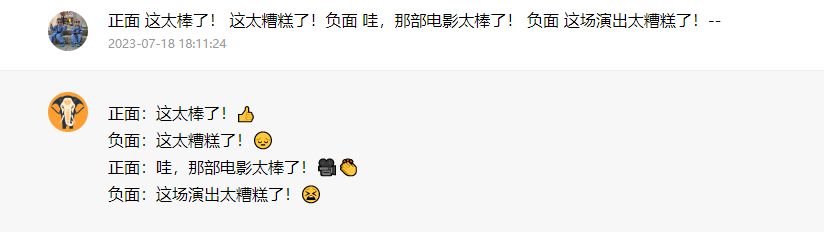
在上述示例中,格式没有一致性,但模型仍然预测出了正确的标签。我们需要进行更深入的分析,以确认这一点是否适用于不同和更复杂的任务,包括提示的不同变化。
少样本提示的局限性
标准的少样本提示对许多任务都有效,但仍然不是一种完美的技术,尤其是在处理更复杂的推理任务时。让我们演示一下为什么会这样。你还记得我们之前提供的示例吗?该示例是:
这个组中的奇数相加得到一个偶数: 15, 32, 5, 13, 82, 7, 1.
A:
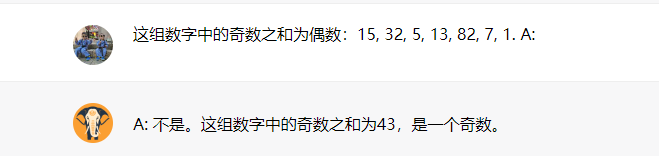
这不是正确的回答,这不仅突显了这些系统的局限性,还表明了需要更高级的提示工程技术。让我们尝试添加一些示例,看看少样本提示是否能改善结果。
这组数字中的奇数之和为偶数:4, 8, 9, 15, 12, 2, 1.
A: 答案是 False.
这组数字中的奇数之和为偶数:17, 10, 19, 4, 8, 12, 24.
A: 答案是 True.
这组数字中的奇数之和为偶数:16, 11, 14, 4, 8, 13, 24.
A: 答案是 True.
这组数字中的奇数之和为偶数:17, 9, 10, 12, 13, 4, 2.
A: 答案是 False.
这组数字中的奇数之和为偶数:15, 32, 5, 13, 82, 7, 1.
A:

这似乎没有起作用。对于这种类型的推理问题,几个示例并不足以获得可靠的回答。上面的示例提供了任务的基本信息,但如果仔细观察,我们引入的任务类型涉及了更多的推理步骤。换句话说,如果我们将问题分解为步骤并向模型展示,可能会有所帮助。最近,链式思维提示(CoT)变得流行,用于解决更复杂的算术、常识和符号推理任务。
总的来说,提供示例对于解决某些任务是有用的。当零-shot提示和少-shot提示不足以解决问题时,这可能意味着模型学到的内容还不足以在任务上表现良好。从这里开始,建议开始考虑对模型进行微调或尝试更高级的提示技术。接下来我们将介绍一种受欢迎的提示技术,即链式思维提示,它在许多方面已经获得了很大的关注。
三、思维链提示词 (Chain-of-Thought Prompting)
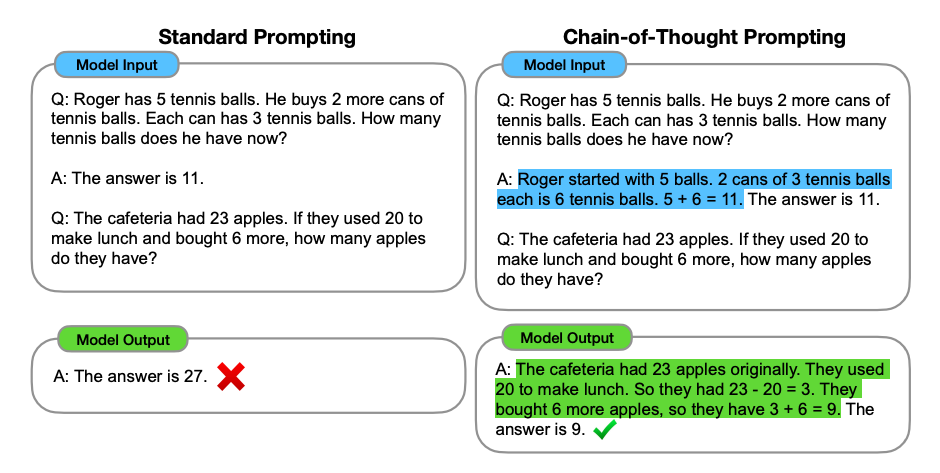
链式思维提示 (Chain-of-Thought Prompting) 是在 Wei 等人(2022年)的研究中引入的,通过中间推理步骤实现复杂推理能力。你可以将它与少-shot提示相结合,以在需要在回答前进行推理的更复杂任务上获得更好的结果。
这个组中的奇数相加得到一个偶数:4, 8, 9, 15, 12, 2, 1。
A: 将所有奇数相加(9, 15, 1)得到25。答案是False。
这个组中的奇数相加得到一个偶数:17, 10, 19, 4, 8, 12, 24。
A: 将所有奇数相加(17, 19)得到36。答案是True。
这个组中的奇数相加得到一个偶数:16, 11, 14, 4, 8, 13, 24。
A: 将所有奇数相加(11, 13)得到24。答案是True。
这个组中的奇数相加得到一个偶数:17, 9, 10, 12, 13, 4, 2。
A: 将所有奇数相加(17, 9, 13)得到39。答案是False。
这个组中的奇数相加得到一个偶数:15, 32, 5, 13, 82, 7, 1。
A:

当我们提供推理步骤时,我们可以看到一个完美的结果。事实上,我们可以通过提供更少的例子来解决这个问题,即只提供一个例子似乎已经足够了。
这组数中的奇数累加起来是一个偶数:4,8,9,15,12,2,1。
A: 把所有的奇数相加(9,15,1)得到25。答案是错误的。
这组数中的奇数累加起来是一个偶数:15,32,5,13,82,7,1。
A:

请记住,这是一种在具有足够大的语言模型的情况下产生的新兴能力。
零样本思维链Zero-Shot-CoT

最近提出的一个新观点是零样本 COT,其基本上是在原始提示的基础上添加了“让我们逐步思考”。我们来尝试一个简单的问题,看看模型表现如何:
我去市场买了10个苹果。我给了2个苹果给邻居,还给了2个苹果给修理工。然后我又买了5个苹果,吃掉了1个。我剩下多少个苹果呢?我们分步骤思考这个问题。

这个简单的提示在这个任务上非常有效,令人印象深刻。这在你没有太多示例可供在提示中使用的情况下特别有用。
自动思维链Auto-CoT
当应用带有示范的思维链提示时,这个过程涉及手工创建有效和多样化的示例。这种手工努力可能导致次优解。有人提出了一种方法,通过利用带有“让我们逐步思考”提示的语言模型来自动生成一步一步的推理链,从而消除手工努力。这个自动过程仍然可能在生成的链条中出现错误。为了减轻错误的影响,示范的多样性至关重要。该方法提出了Auto-CoT自动思维连,它通过抽样具有多样性的问题,并生成推理链来构建示范。
Auto-CoT包括两个主要阶段:
第1阶段:问题聚类:将给定数据集的问题分成几个簇
第2阶段:示范抽样:从每个簇中选择一个代表性问题,并使用Zero-Shot-CoT和简单的启发式方法生成其推理链
简单的启发式方法可以是问题长度(例如60个标记)和推理的步骤数量(例如5个推理步骤)。这可以鼓励模型使用简单而准确的示范。
下面是该过程的示意图:

下面是Auto-CoT的github链接https://github.com/amazon-science/auto-cot
标题:Prompt Engineering 提示词工程研究指南:五、提示词编写技巧(上)
作者:michael
地址:https://blog.junxworks.cn/articles/2023/07/18/1689676540927.html