大数据学习二开源大数据技术栈介绍
Hadoop与Spark开源大数据技术架栈
目前大数据开源技术太多了,很多公司都有自己的大数据技术栈,经过大家验证后最常用的,就是以Hadoop和Spark为核心的生态系统了。之前说过,大数据技术分为6层,下面给出除了数据可视化层以外的5层的Hadoop生态圈的开源工具。
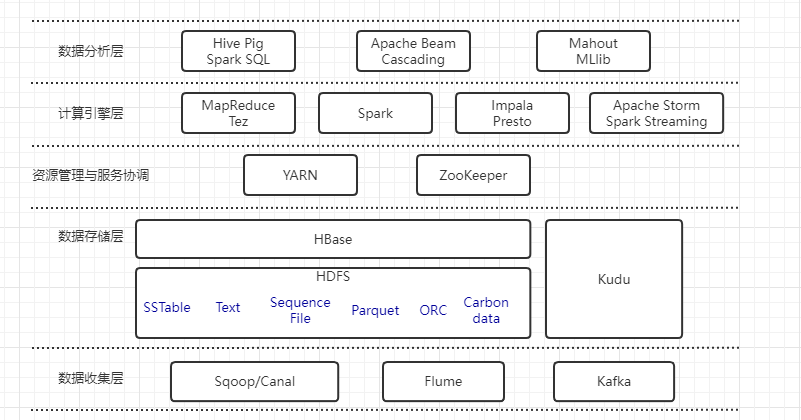
数据收集层
Sqoop/Canal:关系型数据库与大数据存储的桥梁,也就是用来导数据的,将数据从关系型数据库导入到大数据存储中,Sqoop用来做数据库的全量导入。canal是阿里开源的产品,可以用来做增量导入,目前canal主要支持mysql,可以参考这篇文章http://www.importnew.com/25189.html。
Flume:非关系型数据库的数据采集工具,可以近实时的收集流式日志的工具,经过过滤,聚集后,加载到HDFS等存储系统。
Kafka:分布式消息队列,一般作为数据总线使用,基于发布/订阅的模式设计,很适合大数据场景中流式数据的导入。
数据存储层
存储这块主要由分布式文件系统和分布式数据库构成。
HDFS:基于google GFS的开源实现,具有良好的扩展性和容错性,很适合构建在廉价的服务器上,大大节约成本,目前能支持多种类型的数据存储格式,例如SSTable(Sorted String Table)、文本文件、二进制key/value格式的sequence file、列式存储格式Parquet、ORC和Carbondata等。
HBase:构建在HDFS之上的分布式数据库,是列式存储数据库,google BigTable的开源实现,允许存结构化和半结构化数据,支持行列无限扩展以及数据随机查找与删除。
Kudu:分布式列式存储数据库,允许用户存储结构化数据,支持行无限扩展以及数据随机查找与更新。
资源管理与服务协调
YARN:统一资源管理与调度系统,统一管理整个集群的各种资源,例如CPU、内存。支持多租户,多策略。
ZooKeeper:用作分布式服务协同,网上资料一大堆,非常成熟的开源产品。
计算引擎层
包含了批处理、交互式处理与流式处理三种引擎。
MapReduce/Tez:MapReduce是经典的批处理计算引擎,也是基于google的MapReduce实现的开源版本,允许用户用API编写分布式程序。Tez是基于MapReduce开发的通用DAG(Directed Acyclic Graph,有向无环图)计算引擎,能够更加高效的实现复杂的数据处理逻辑,目前被应用在Hive、Pig等数据分析系统中。
Spark:通用的DAG计算引擎,目前使用最广的计算引擎,提供了基于RDD(Resilient Distributed Dataset)的数据抽象表示,允许用户在内存中快速的进行数据挖掘和分析。
Impala/Presto:分别有Cloudera和Facebook开源的MPP系统,允许用户使用标准SQL处理存储在Hadoop中的数据。采用了并行架构处理,内置查询优化器、查询下推、代码生成等优化机制,使得大数据处理效率大大提升。
Storm/Spark Streaming:分布式流式实时计算引擎,具有良好的容错性与扩展性,能够高效的处理流式数据。阿里还开源了一个JStorm,效率比storm要高,可以参考https://www.aliyun.com/jiaocheng/topic_26352.html。
数据分析层
方便用户分析数据提供的各类数据分析工具。
Hive/Pig/SparkSQL:构建在大数据计算引擎之上的,支持SQL语言或者脚本语言的分析系统。Hive是基于MapReduce/Tez实现的SQL引擎,Pig跟Hive差不多(我也没用过具体可以问度娘)。SparkSQL是基于Spark实现的SQL引擎。
Mahout/MLlib:实现了用于机器学习和数据挖掘的算法。Mahout是基于MapReduce实现的,MLlib是基于Spark实现的。
Apache Beam/Cascading:基于各类计算框架封装的高级API,方便用户构建复杂的数据流水线。Apache Beam统一了批处理和流式处理两类计算框架,提供了更高级的API方便用户编写与具体计算引擎无关的逻辑代码。Cascading内置了查询计划优化器,能够自动优化用户实现的数据流,如果你的数据可以表示成类似于数据库的行格式,则使用Cascading处理将变得很容易。