大数据学习一大数据技术架构分层
初识大数据
目前很多行业都涉及到大数据处理技术,像大数据技术领军行业互联网行业,其他领域目前也逐步推广大数据技术,例如电信、医疗、金融、交通等。本人工作九年多,一开始便接触编程,但是之前一直是做服务器后端开发,也做过全栈开发,偶尔有接触过大数据,但是一直没有深入学习,这对于喜欢技术的我而言,稍有后悔,大数据成为目前程序猿的标准技能,以后想成为架构师的同学也应该引起重视,大数据是不可或缺的。由于公司转型,想涉足大数据方面的研发,因此下定决心,往大数据方向更进一步去了解学习。
大数据技术架构分层
目前最新的大数据架构一共分为6层,分别是:数据收集层、数据存储层、资源管理与服务协调层、计算引擎层、数据分析层、数据可视化层。如图所示: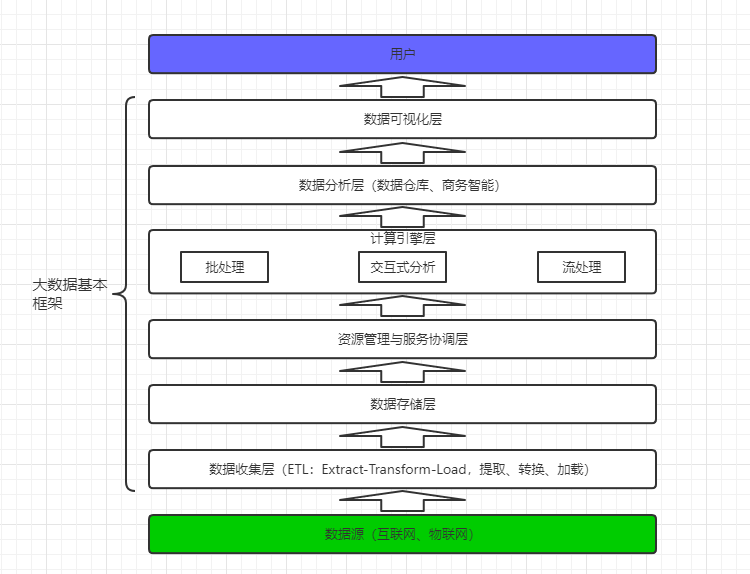
数据收集层
数据收集层或者数据采集层,目的是把数据源的数据收集到一起去存储,数据收集的过程可以是实时的也可以是近实时的。需要采集的数据源一般具有分布式、异构性、多样化、流式产生等特点:
分布式:数据源一般分布在多台服务器上,例如日志文件。
异构性:任何能产生数据的设备或者应用程序都可以成为数据源,例如:web服务器、数据库、传感器、手环、视频监控设备等。
多样化:数据源产生的数据格式是多样的,例如用户信息这种结构化数据、或者视频、图片这种非结构化数据。
流式产生:数据源就像“水龙头”一样,源源不断的产生数据,数据收集系统将数据实时或者准实时的发送到后端,以便对数据进行分析处理。
由于数据源具有以上特性,那么数据收集工具需要处理很多问题,才能保证数据完整的、安全的、准时的送往后端,因此数据采集层必须具备以下特点:
可扩展性:能够灵活配置适合采集多种类型的数据源,而且接入大量数据源不能产生系统瓶颈。
可靠性:数据传输过程中不能丢失,或者在业务允许的范围内少量丢失。
安全性:有些业务数据是敏感的,必须要保证敏感数据不会产生安全隐患。
低延迟:数据源产生的数据非常庞大,必须保证数据准时的送到后端存储系统中去。
数据存储层
数据存储主要负责结构化和非结构化的数据存储。大数据时代的数据量特别大,对扩展性、容错性和存储容量有严格要求,普通的关系型数据库例如mysql或者linux文件系统难以适应大数据的引用场景,因此大数据时代的数据存储层必须要有以下特点:
扩展性:数据量随着业务发展,会越来越多,随时可能需要增加存储节点,因此存储系统本身需要有非常好的线性扩展能力。
容错性:机器在出现故障的时候,必须要保证数据不丢失。
存储模型:数据具有多样性,存储层应该支持多种数据模型,保证结构化数据和非结构化数据的存储。
资源管理与服务协调层
大数据系统中,存在很多开源产品需要做HA的,如果每类应用单独做集群,那么需要大量的服务器,而且有可能造成资源的浪费,毕竟不是时时刻刻每个产品的资源利用率都很高。因此出现了资源管理系统,将所有大数据的应用整合到一个统一的服务器集群进行管理,共享集群资源,采用轻量级的应用隔离方案对各个应用进行隔离,具有资源利用率高、运维成本低、数据共享等好处。
引入服务协调层,主要是为了引入leader选举、服务命名、分布式队列、分布式锁、发布订阅等常用开发分布式系统所需的功能。
计算引擎层
数据进入存储层后,要想业务或者用户能用,必须要进过计算处理,而且不用的应用场景,需要有不同的计算能力。目前常用的计算引擎分为三类:批处理、交互式处理、实时处理。
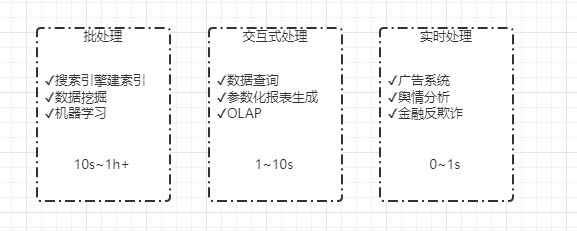
批处理:适合对实时性要求不高的场景,但是对系统吞吐率高,即单位时间内处理的数据量尽可能大。典型应用场景例如搜索引擎构建索引、批量数据分析等。
交互式处理:对系统响应时间要求比较高,一般要求处理时间为秒级,这类系统需要人机交互,因此会提供类似SQL的语言方便用户使用,典型应用场景如数据查询、参数化报表生成等。
实时处理:对系统响应时间要求最高,一般处理时间要求为毫秒级,典型的应用如广告系统、舆情监测等。
数据分析层
数据分析层直接跟用户的应用程序对接,为其提供易用的数据处理工具。为了用户更方便的分析数据,计算引擎会提供多样化的工具,例如API接口、类SQL查询语言、数据挖掘SDK等。一般情况可能会多种分析工具结合使用,例如先用批处理框架对原始海量数据进行分析,产生一个小规模的数据集,在此基础上,再用交互式处理工具对该数据集进行快速查询,获取最终结果。
数据可视化层
数据可视化技术指的是运用计算机图形学和图像处理技术,将数据转换成为图形或者图像在屏幕上显示出来,并进行交互处理的理论、方法和技术。
大数据技术架构目前这6层都有具体的开源工具来支撑,其中Google的技术最为牛逼,很多开源产品都是基于Google提出的理论进行开发和设计的,后面继续分析大数据技术架构的各层使用的开源工具。