Flink入门1
一:Flink是什么?
Flink是一个分布式计算框架。
Flink可以搭建廉价机群,快速处理任意规模的数据。
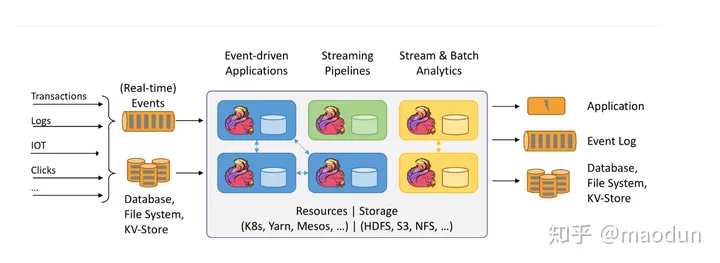
Flink总体架构如图,从左往右看。
Flink的实时处理是一个个Event(事件)驱动的(类比Kafka,Flume),不同于Spark Streaming中微批次。
(1)Flink的架构
简单理解无界流和有界流
无界流:流数据不会停止,没有边界,需要实时处理,绝对的实时处理,来一条,处理一条。
有界流:定义了数据的范围,类比Spark-Streaming中的微批次处理,Hive离线Mr处理。
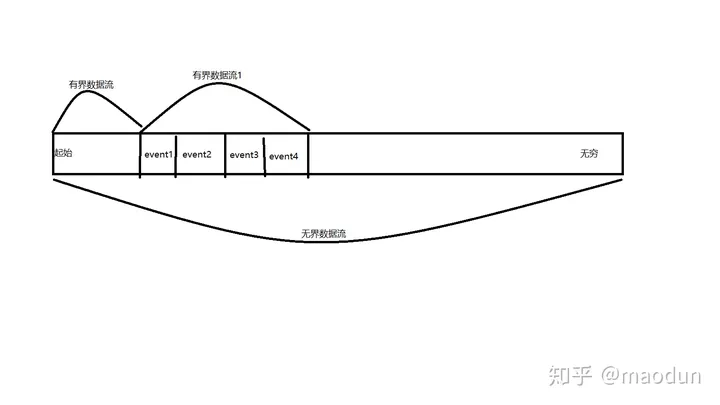
Flink擅长于处理无界数据流(例如Kafka里的日志数据),有界数据集。
Fink可以部署在Yarn,K8s,Mesos多种资源调度框架中。
Fink可以处理任意数据量级。
- 上万亿的Event处理。
- 维护TB级别的处理状态。(类比Spark RDD中Cache,持久化TB级别的处理状态)
- 运行在上千个核心的机群中。
Flink的状态持久化的优化
- 当Flink计算Task中内存不足时候,Flink通过特殊的数据结构,高效的持久化到本地磁盘。
- Flink会周期的异步持久化计算状态,防止Task进程挂掉,Task 主机意外宕机。并保证持久化数据的一致性。
- Flink提供了CheckPoint,可以异步的将计算状态持久化到持久层(如HDFS,本地文件系统)
(2)Flink的应用
关于流处理的一些基本概念
流处理:
- Flink可以处理有界或无界数据,提供了强力的无界数据处理的特性。
- Flink更加偏向绝对的实时处理,来一条处理一条,而不是微批次。
状态:
计算状态是Flink的一等公民,Flink提供了许多特性来处理状态。
分层API
Flink提供了不同级别的API,满足各种应用场景的应用需求(类比RDD和Spark SQL)
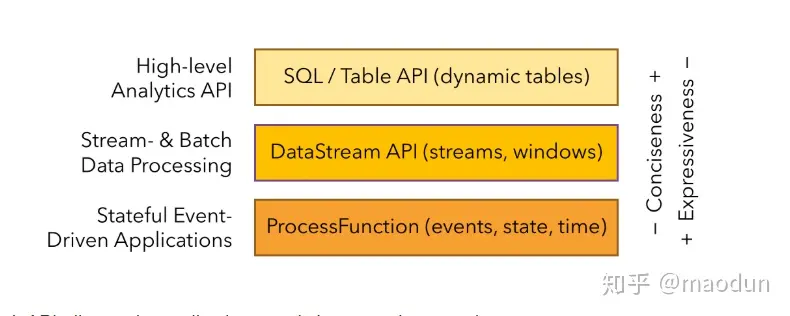
ProcessFunction对应RDD,DataStream对应Spark Streaming, SQL/Table API对应Spark SQL
总结:
官网介绍的更加详细,有兴趣可以自行看下(有中文版,牛逼吧,有中文版)。
Flink实时处理很强,提供的ProcessFunction API可以非常细粒度灵活的控制Event处理。
Flink的提供了SQL支持,对Event进行数据聚合后,使用SQL进行数据分析。
Flink是来一个Event处理一次,对比按照时间间隔微批次处理,所以保证了数据实时处理。
Flink对计算状态持久化提供了非常多的特性。
二:Flink demo项目
Maven POM, 注意使用Scala2.11, 如果你想用Flink1.9,请选择Scala2.12。
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>1.7.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-scala -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.7.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- 该插件用于将Scala代码编译成class文件 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.4.6</version>
<executions>
<execution>
<!-- 声明绑定到maven的compile阶段 -->
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
第一个WorkCount.scala
import org.apache.flink.api.scala.ExecutionEnvironment
//隐式转换
import org.apache.flink.api.scala._
object WordCount {
def main(args: Array[String]): Unit = {
//获取Flink运行环境
val environment = ExecutionEnvironment.getExecutionEnvironment
//注意 readTextFile路径填你自己的文件路径。
val testDataSet = environment.readTextFile("1.txt")
//可以理解testDataSet为一个RDD
//groupby(0)意思是以元组第一个为key进行分组,sum(1)是对元组第二个位置数据进行累加。
val result = testDataSet.flatMap(_.split(" ")).map((_, 1)).groupBy(0).sum(1)
result.print()
}
}
1.txt
hello java
hello java
hello flink
hello flink
运行结果
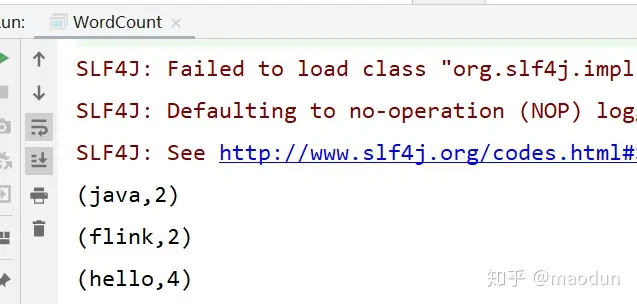
Flink Sock实时统计
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.api.scala._
object SockDStream {
def main(args: Array[String]): Unit = {
val environment = StreamExecutionEnvironment.getExecutionEnvironment
val unit = environment.socketTextStream("192.168.208.102", 7777)
val result = unit.flatMap(_.split(" ")).filter(_.nonEmpty).map((_, 1)).keyBy(0).sum(1)
result.print()
//执行
environment.execute()
}
}
linux 192.168.208.102 虚拟机内
#如果没有netcat请先安装
yum install -y nc
#启动sock隧道
nc -lk 7777
运行SockDStream.scala
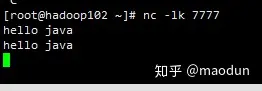

Flink默认是状态保持的(输入两个hello java, 输出 hello 2, java 2),默认保存在内存内
三:Flink的部署
单节点模式
配置Jdk1.8以上的环境变量
上传至Linux服务器,解压。
tar xf flink****.tar -C {指定目录}
./bin/start-cluster.sh
http://{节点Ip}:8081为Flink WebUI
机群搭建
Flink机群相对来说配置比较简单
配置Jdk1.8,同样的步骤, 上传解压。
注意机群模式需要配置主机访问从机的SSH免密。
编辑配置文件 vi conf/flink-conf.yaml
注意yaml文件 冒号后必须加一个空格再填写参数。
jobmanager.rpc.address: (此项设置为主机IP地址设置)
编写conf/slaves文件,填加从机IP地址。
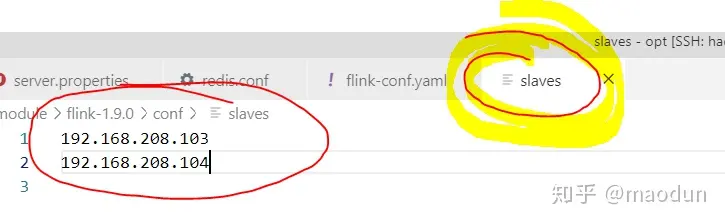
从机配置地址
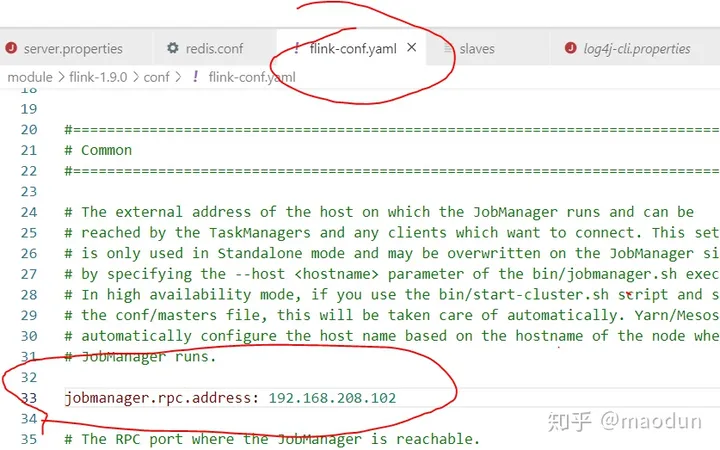
主机Ip地址配置
分发文件到从机,分发脚本如下。
#!/bin/bash
pcount=$#
if((pcount==0)); then
echo no args;
exit;
fi
p1=$1
fname=`basename $p1`
echo fname=$fname
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
user=`whoami`
//注意下一行你必须修改,换成主机名,或者你的IP
for((host=102;host<105;host++)); do
echo --------hadoop$host--------
rsync -rvl $pdir/$fname $user@hadoop$host:$pdir
done
启动机群
bin/start-cluster.sh
查看Web UI
{主机地址}:8081