二、Stable Diffusion 赛博丹炉LoRA模型训练参数
参数调优
1. 训练参数分析
必看视频!!! [全网最细lora模型训练教程]这时长?你没看错。还教不会的话,我只能说,师弟/妹,仙缘已了,你下山去吧!_哔哩哔哩_bilibili
1.1 步数相关 repeat / epoch / batch_size

【1】epoch多轮次比单轮次要好,通过设置可以每轮保存一组模型,多轮次说明有多组模型,得到好概率的可能是比单轮次就一个模型的概率是要高的,epoch一般设置5~10;
【2】batch_size要是高,一是可能显存带不动,二是值越高训练越快 越可能学得囫囵吞枣收敛得慢。

BS从1到2,Ir就要*2
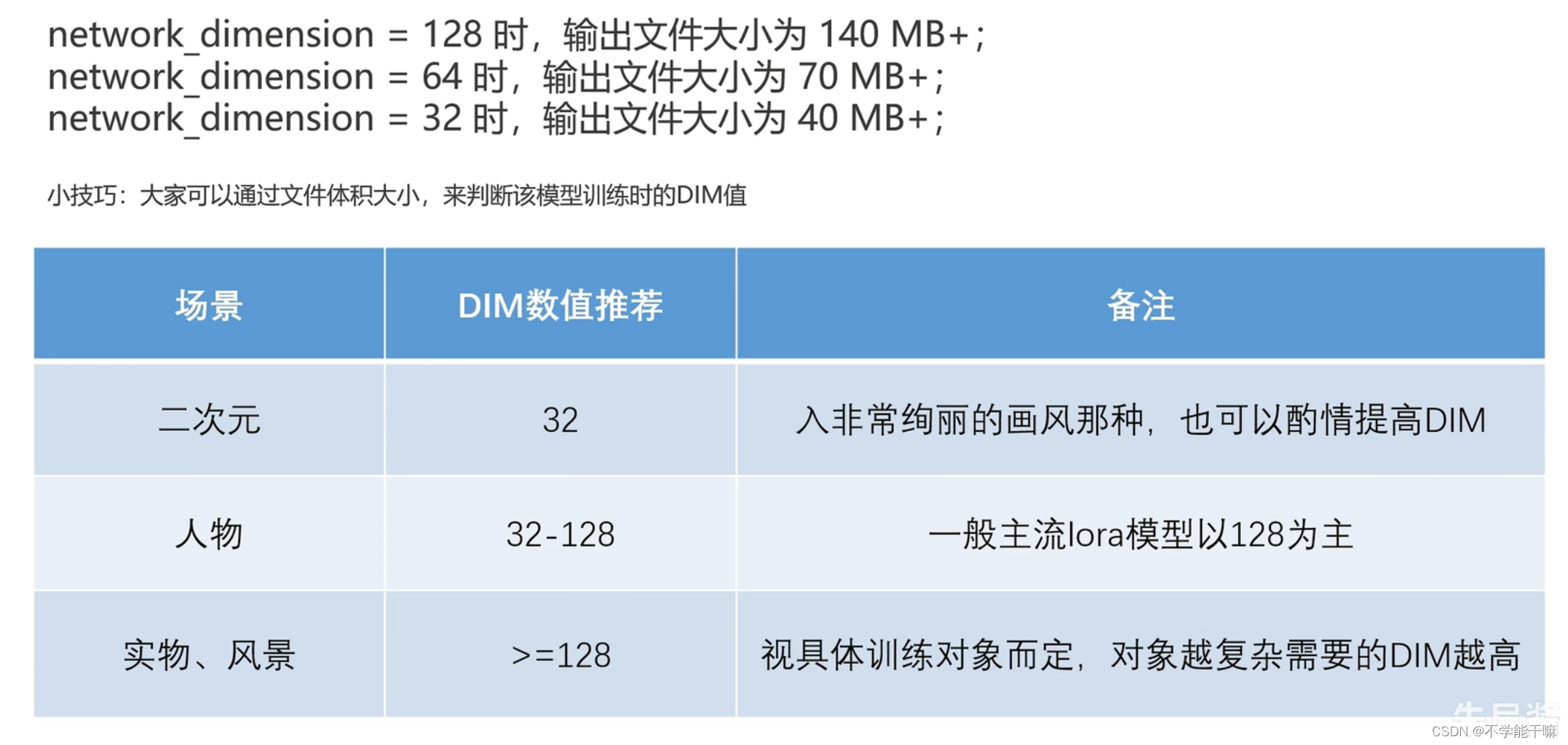
1.2 速率/质量相关 Ir学习率 / Dim网络维度 / Optimizer优化器

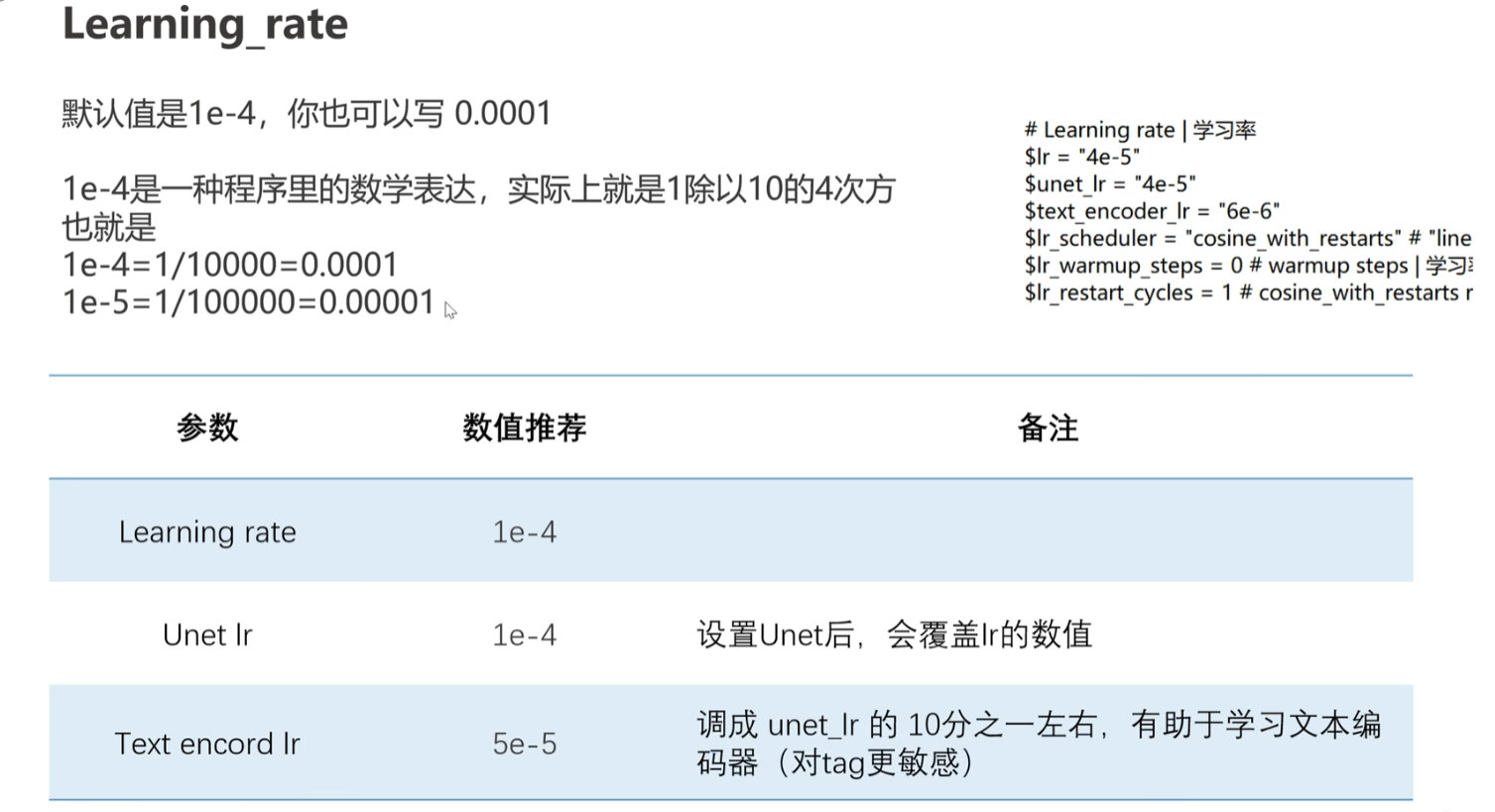
学习率Ir,控制了每次参数更新的幅度,过低参数更新幅度小 训练收敛就慢 陷入局部最优解 训练时间增加,过低也会导致训练初期无法有效学习到特征;过高,参数更新幅度大 错过全局最优解附近的局部最优解 找不到稳定的收敛点,常用cos的学习率衰减策略,初始使用较大的学习率快读接近全局最优解,在随着训练的进行逐渐减小学习率,使得逐渐细化搜索空间,找到全局附近的局部最优解,提高收敛的稳定性。
前面提到的“bs提高,Ir也要提高”是因为bs较大时会导致参数更新的方差减小从而使得梯度更新幅度也减小,这时就需要Ir也相应地增大。我这里还在思考bs、Ir都提高了的话,训练速度是不是也会大幅度提高?chat告诉我不一定,因为bs大占用的内存和计算量也增加,Ir大模型容易不稳定不收敛,理论上肯定是会增加训练速度,但实际上还是要根据你的显卡来设置bs值,训练速度变向是看钞能力,跑起来才是王道,先优先考虑生成效果再训练速度吧~
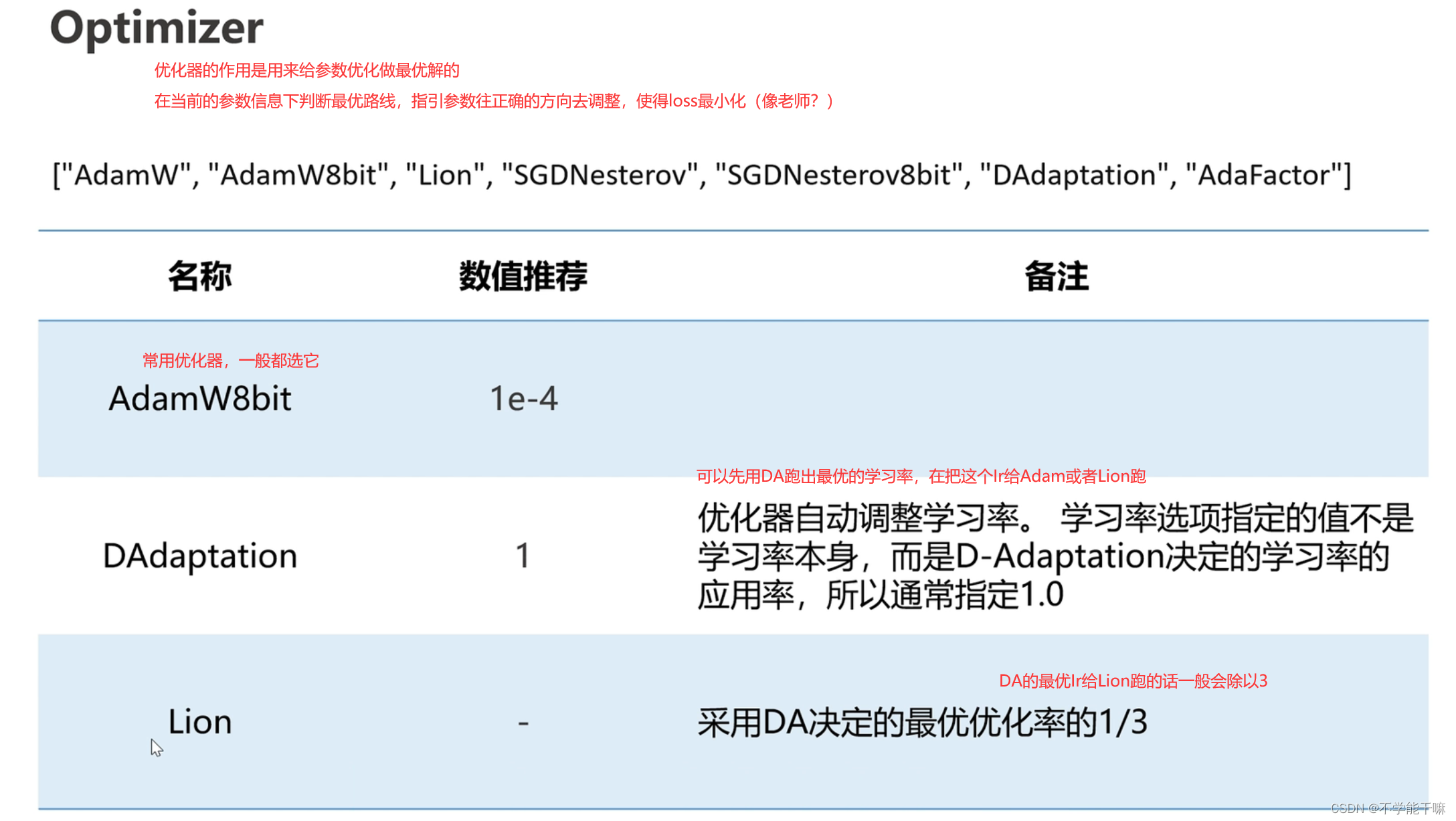
优化器(Optimizer) - 知乎 (zhihu.com)
Lion比AdamW8bit的优点是更快,总训练步数在3k-1w内都可以考虑选它。
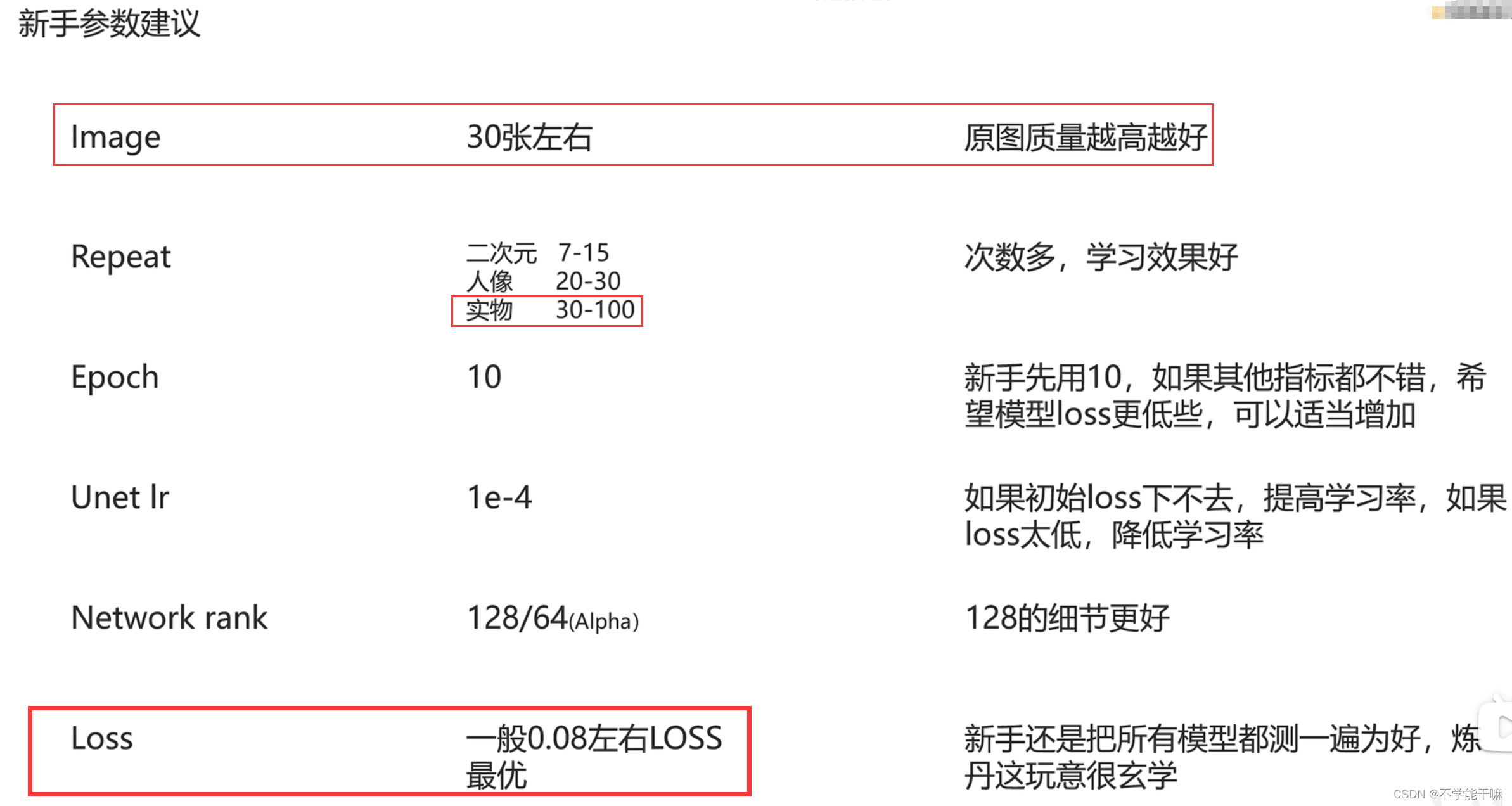
图像这里居然不要很多,作者这里是考虑到耗费时间等因素,我觉得有道理,如果我训练效果不好,我将尝试将重新创建我的数据集,只选出质量最高的30来张图像来做训练。
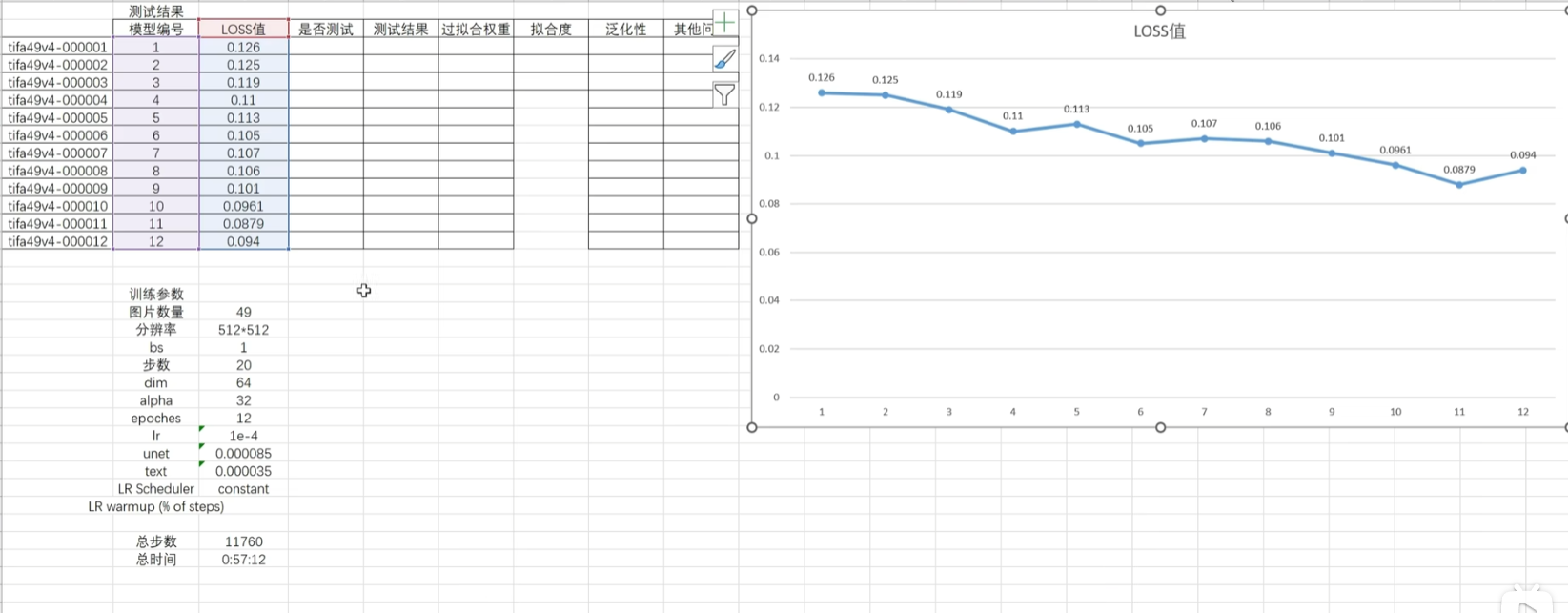
loss值的最优区间0.07-0.09,但loss值只是一个参考,但更多的还是要通过XYZ测试来看模型的好坏,原图VS根据原图tag测试模型生成的图片。

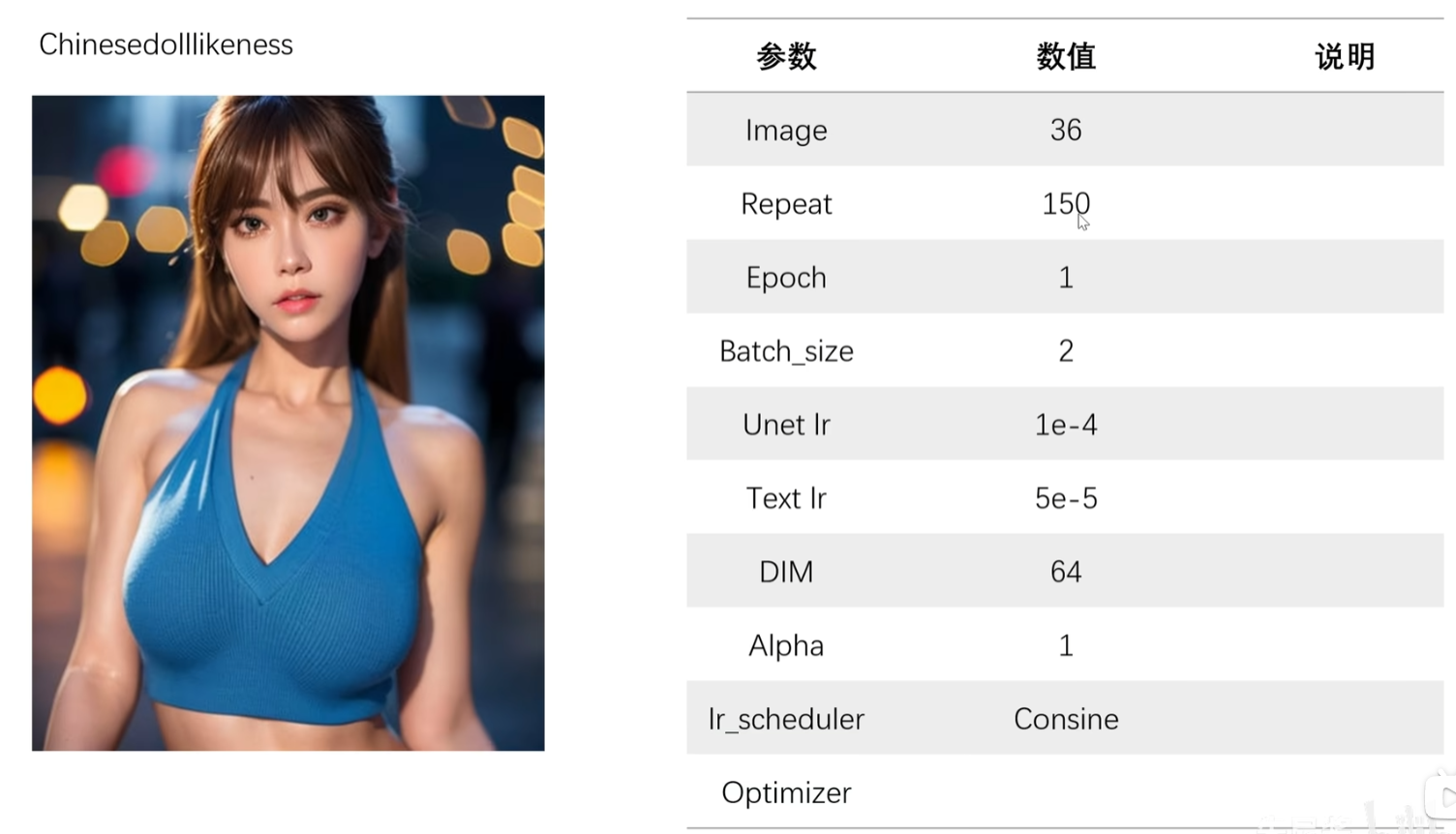
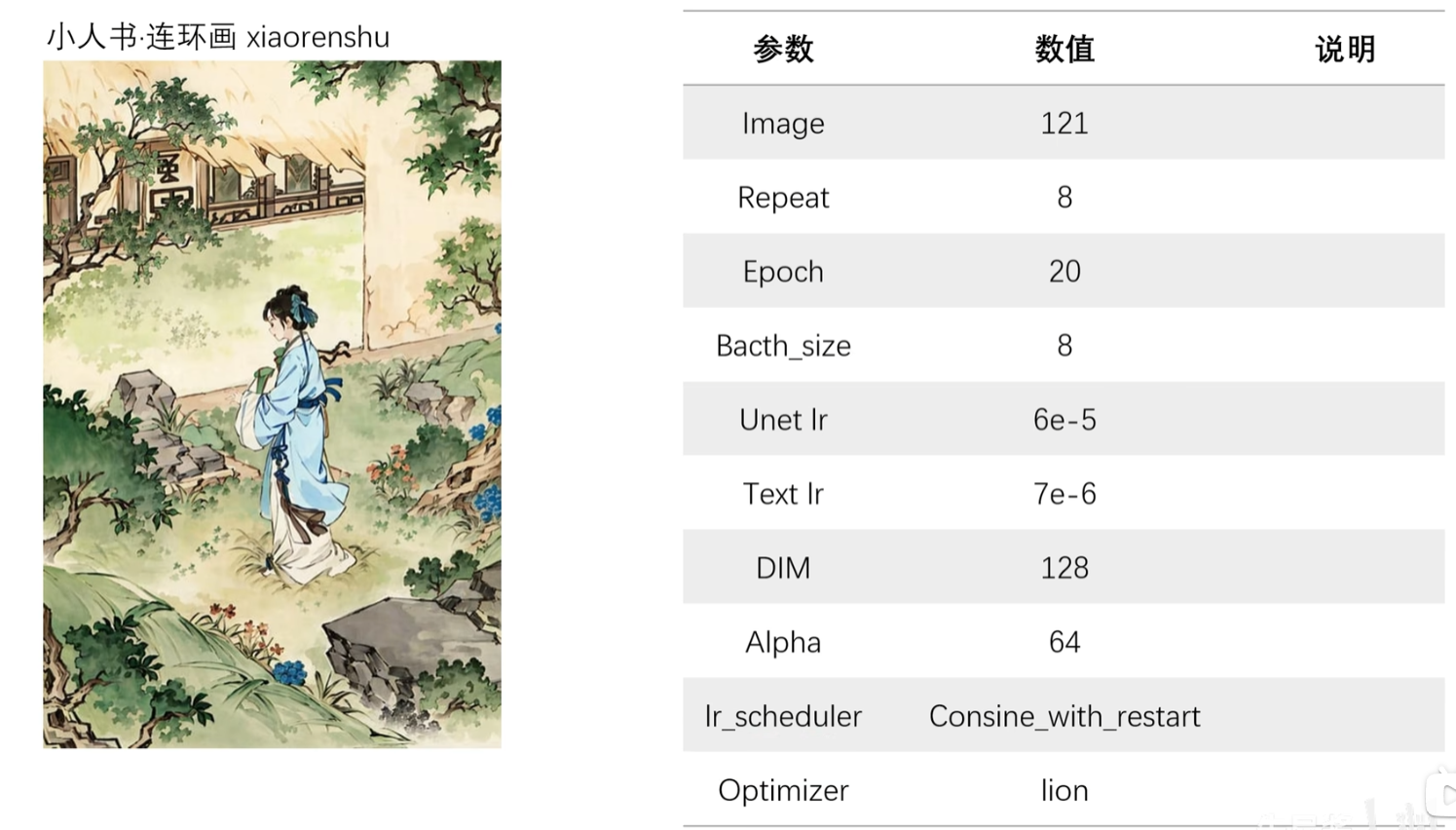
参数例子:

2.实际操作
2.1 选择底模
先提前选择下载好要训练的底模,底模的选择也很关键,后面有报错就是因为底模有些东西不对,搞了两天,千算万算没想到是底模的问题,放模型的位置也有点玄学讲究,具体看你选择一下哪种工具来训练。
stable diffusion 常用大模型解释和推荐(持续更新ing) - 知乎 (zhihu.com)
【LoRA训练用什么底模】最新LoRA训练进阶教程6_哔哩哔哩_bilibili

选择的底模要画风一致的,分为二次元动漫类/2.5次元游戏类/三次元现实类,实际上不同画风之间的转换是不容易的,先确定底模和你的需求的画风一致。 我要训练的是三次元的物体,目前在尝试用v1.5-pruned模型训练,有推荐说炼亚洲人用ChilloutMix。
另外,大家在下载模型的时候,会看到pruned、emaonly(ema)之类的后缀,pruned是完整版,emaonly是剪枝版。剪枝版比完整版通常小很多,方便下载。如果只是使用的话,两者差别不大,如果是想要自己练模型的话,需要下载完整版。
2.2 Tag示例
Tag越丰富越好,尽量描述全,自动生成的tag不齐的,需要人工补齐



2.3 训练流程
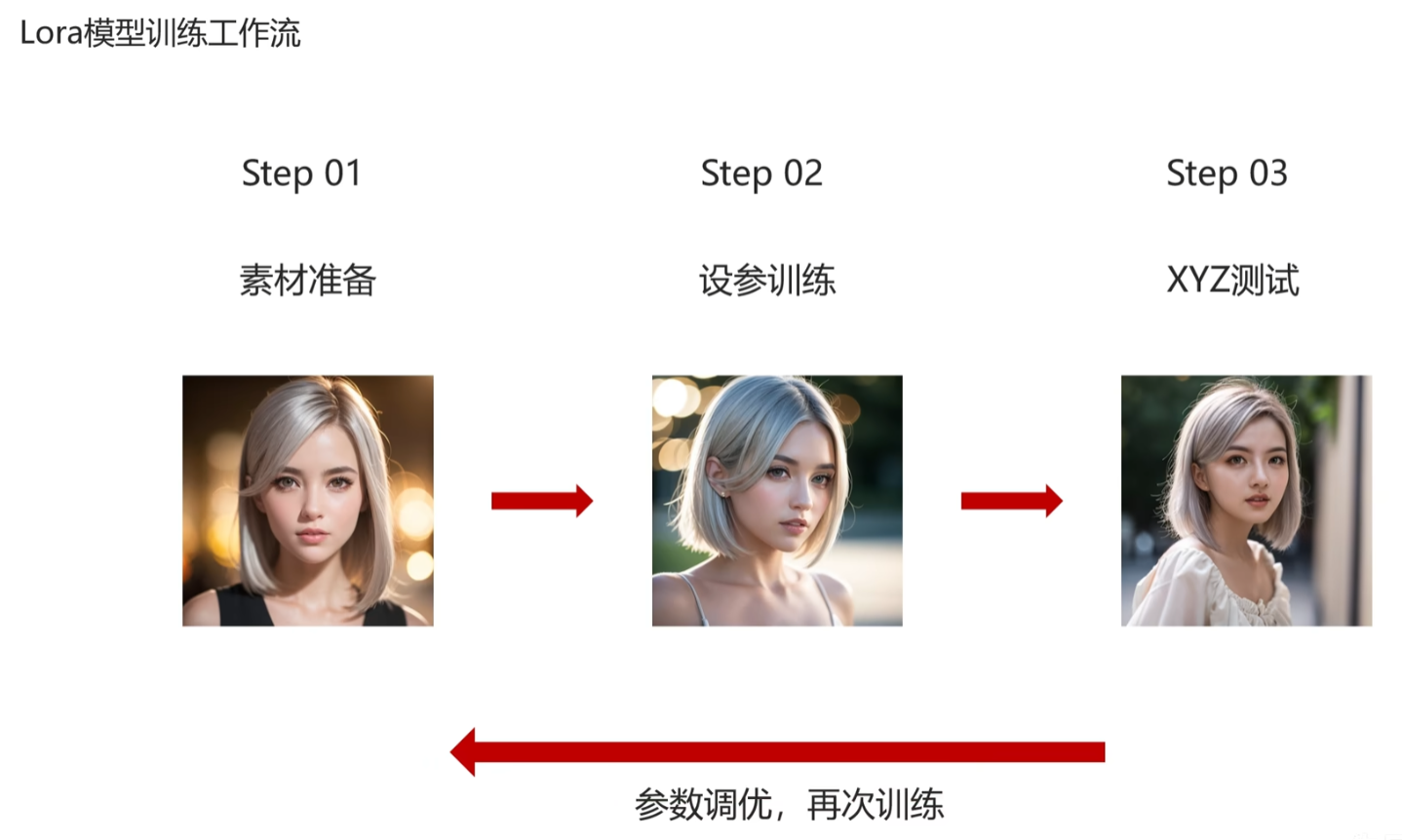
学习完成后,最好记录一下各个模型的loss值
参考文章:https://blog.csdn.net/m0_59805198/article/details/135070297
标题:二、Stable Diffusion 赛博丹炉LoRA模型训练参数
作者:michael
地址:https://blog.junxworks.cn/articles/2024/02/25/1708842266779.html