Sharding-JDBC自定义复合分片算法ComplexKeysShardingAlgorithm多字段分表实践
最近做一个自己的项目,遇到一个比较大的表,股票统计相关需求,5000只股票,1年240个交易日,每个交易日每只股票大概有200个统计指标,也就是每个交易日100万条数据,每月2000万,每年2.4亿条数据,这种表随着股票数量越大,或者统计指标的增加,数据量会增长得很快,这时候就不能单纯的按年或者按股票来分了,还是需要先分析使用场景,这种统计指标表,正常情况下的查询还是要带股票的ts代码的,不会全量统计,这样首先就基于股票的ts代码来分表,但是只以ts代码来分还不好,随着时间的推移数据量依然增长的很快,因此还得加入日期分片键,我这里按日期的年月来切分,ts代码分5个,年月是12个,所以每一年的分表有60个,平均每张表400万条数据左右,这里有预留,后期可以加统计指标。
下面是复合字段分片算法TsCodeTradeDateShardingAlgorithm的实现:
public class TsCodeTradeDateShardingAlgorithm implements ComplexKeysShardingAlgorithm<String> {
private static final Date START = DateUtils.parseDate("2015-01-01");
private static final Date END = DateUtils.parseDate("2030-01-01");
private static final int count = 5;
private static final String COLUMN_TSCODE = "key_value";
private static final String COLUMN_TRADEDATE = "trade_date";
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, ComplexKeysShardingValue<String> shardingValue) {
final Set<String> suffix = Sets.newHashSet();
Map<String, Collection<String>> nasValues = shardingValue.getColumnNameAndShardingValuesMap();
//固定值条件
Set<String> codes = Sets.newHashSet();
Set<String> dates = Sets.newHashSet();
if (nasValues != null && !nasValues.isEmpty()) {
Collection<String> tsCodes = nasValues.get(COLUMN_TSCODE);
if (tsCodes != null && !tsCodes.isEmpty()) {
//有tsCode条件
tsCodes.forEach(c -> {
codes.add(getTsCodeTag(c));
});
}
Collection<String> tradeDates = nasValues.get(COLUMN_TRADEDATE);
if (tradeDates != null && !tradeDates.isEmpty()) {
tradeDates.forEach(d -> {
dates.add(getDateSuffix(d));
});
}
}
//范围条件
Map<String, Range<String>> rangeValues = shardingValue.getColumnNameAndRangeValuesMap();
if (rangeValues != null && !rangeValues.isEmpty()) {
Range<String> tradeDates = rangeValues.get(COLUMN_TRADEDATE);
if (tradeDates != null && !tradeDates.isEmpty()) {
String le = null;
String ue = null;
if (tradeDates.hasLowerBound()) {
le = tradeDates.lowerEndpoint();
}
if (tradeDates.hasUpperBound()) {
ue = tradeDates.upperEndpoint();
}
if (StringUtils.notNull(le) && StringUtils.isNull(ue)) {
Date d = DateUtils.parse(le, "yyyyMMdd");
while (d.getTime() <= END.getTime()) {
dates.add(getDateSuffix(d));
d = DateUtils.addMonths(d, 1);
}
}
if (StringUtils.notNull(le) && StringUtils.notNull(ue)) {
Date d = DateUtils.parse(le, "yyyyMMdd");
Date ud = DateUtils.parse(ue, "yyyyMMdd");
while (d.getTime() <= ud.getTime()) {
dates.add(getDateSuffix(d));
d = DateUtils.addMonths(d, 1);
}
}
if (StringUtils.isNull(le) && StringUtils.notNull(ue)) {
Date d = DateUtils.parse(ue, "yyyyMMdd");
while (d.getTime() >= START.getTime()) {
dates.add(getDateSuffix(d));
d = DateUtils.addMonths(d, -1);
}
}
}
}
if (!codes.isEmpty() && !dates.isEmpty()) {
//都不为空
codes.forEach(c -> {
dates.forEach(d -> {
suffix.add("_" + c + "_" + d);
});
});
} else if (!codes.isEmpty() && dates.isEmpty()) {
//code不为空
codes.forEach(c -> {
suffix.add("_" + c + "_");
});
} else if (codes.isEmpty() && !dates.isEmpty()) {
//date不为空
dates.forEach(d -> {
suffix.add("_" + d);
});
}
if (!suffix.isEmpty()) {
return availableTargetNames.stream().filter(t -> {
for (String s : suffix) {
if (t.contains(s)) {
return true;
}
}
return false;
}).collect(Collectors.toList());
}
return availableTargetNames;
}
private String getTsCodeTag(String tsCode) {
int code = tsCode.hashCode();
return String.valueOf((code < 0 ? (code * -1) : code) % count);
}
private String getDateSuffix(String date) {
return date.substring(0, 6);
}
private String getDateSuffix(Date date) {
return DateUtils.format(date, "yyyyMM");
}
@Override
public void init(Properties props) {
}
}
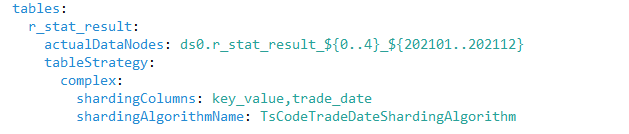
Sharding的配置如下:

标题:Sharding-JDBC自定义复合分片算法ComplexKeysShardingAlgorithm多字段分表实践
作者:michael
地址:https://blog.junxworks.cn/articles/2023/07/27/1690447191753.html