想自己利用OpenAI做一个文档问答的知识库 置顶!
本篇举几个例子来说明如何利用OpenAI Embedding做文档问答,如何进行工程化,工程化的难点与步骤有些什么。了解类似ChatPDF这样应用的实现原理。为后续自己搞一个做预调研!
1 document.ai
1.1 ChatGPT Embedding使用框架
基于向量数据库与GPT3.5的通用本地知识库方案(A universal local knowledge base solution based on vector database and GPT3.5)
流程:
- 将本地答案数据集,转为向量存储到向量数据
- 当用户输入查询的问题时,把问题转为向量然后从向量数据库中查询相近的答案topK 这个时候其实就是我们最普遍的问答查询方案,在没有GPT的时候就直接返回相关的答案整个流程就结束了
- 现在有GPT了可以优化回答内容的整体结构,在单纯的搜索场景下其实这个优化没什么意义。但如果在客服等的聊天场景下,引用相关领域内容回复时,这样就会显得不那么的突兀。
1.2 工程化中的一些优化点
问答拆分查询
在上面的例子中,我们直接将问题和答案做匹配,有些时候因为问题的模糊性会导致匹配不相关的答案。
如果在已经有大量的问答映射数据的情况下,问题直接搜索问题集,然后基于已有映射返回当前问题匹配的问题集的答案,这样可以提升一定的问题准确性。
抽取主题词生成向量数据
因为答案中有大量非答案的内容,可以通过抽取答案主题然后组合生成向量数据,也可以在一定程度上提升相似度,主题算法有LDA、LSA等。
自训练的Embedding模型
openAI 的Embedding模型数据更多是基于普遍性数据训练,如果你要做问答的领域太过于专业有可能就会出现查询数据不准确的情况。
解决方案是自训练 Embedding 模型,推荐一个项目 text2vec
基于 Fine-tune
目前自身测试下来,使用问答数据集对GPT模型进行Fine-tune后,问答准确性会大幅提高。你可以理解为GPT通过大量的专业领域数据的学习后成为了该领域专家,然后配合调小接口中temperature参数,可以得到更准确的结果。
但 现在 Fine-tune 训练和使用成本还是太高,每天都会有新的数据,不可能高频的进行 Fine-tune。一个想法是每隔一个长周期对数据进行 Fine-tune ,然后配合外置的向量数据库的相似查询来补足 Fine-tune 模型本身的数据落后问题。
https://github.com/GanymedeNil/document.aigithub.com/GanymedeNil/document.ai
2 利用ChatGPT 和Milvus快速搭建智能问答机器人
2.1 ChatGPT API简述
ChatGPT以文字方式互动,除了可以透过人类自然对话方式进行交互,还可以用于相对复杂的语言工作,包括自动文本生成、自动问答、自动摘要等在内的多种任务。
ChatGPT 是由 OpenAI 最先进的语言模型 gpt-3.5-turbo 提供支持, GPT-3.5-turbo 模型是以一系列消息作为输入,并将模型生成的消息作为输出。
# Note: you need to be using OpenAI Python v0.27.0 for the code below to work
import openai
openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}
]
)
消息是一个对象数组,其中每个对象都有一个角色,一共有三种角色。
- 系统 消息有助于设置助手的行为。在上面的例子中,助手被指示 “你是一个得力的助手”。
- 用户 消息有助于指导助手。 就是用户说的话,向助手提的问题。
- 助手 消息有助于存储先前的回复。这是为了持续对话,提供会话的上下文。
我们调用的ChatGPT的API是无状态的,意味着你需要自己去维持会话状态,保存上下文,每次请求的时候将之前的历史消息全部发过去,但是这里面有两个问题:
-
- 为了建立持续会话,请求内容会越来越大,这些内容前后的关联关系并不是很大;
-
- 语言模型以称为 tokens 的块读取文本,需要为为每个 token 支付费用,这样Token 费用很高。
-
- 为了保证API调用的有效性,令牌总数必须是 低于模型的最大限制(gpt-3.5-turbo-0301 为 4096 个令牌)
我们借助OpenAI的embedding模型和自己的数据库,先在本地搜索数据获得上下文,然后在调用ChatGPT的API的时候,加上本地数据库中的相关内容,这样就可以让ChatGPT从你自己的数据集获得了上下文 ,再结合ChatGPT自己庞大的数据集给出一个更相关的理想结果。
2.2 整体架构
本文通过语义相似度匹配来实现一个问答系统,大致的构建过程:
- 获取某一特定领域里大量的带有答案的中文或者英文问题(本文将之称为标准问题集),把它变成CSV或者Json这样易于处理的格式,并且分成小块(chunks),每块不要超过8191个Tokens,因为这是OpenAI embeddings模型的输入长度限制。
- 使用OpenAI的embedding模型将这些问题转化为特征向量,需要将转换后的结果保存到本地数据库。 注意一般的关系型数据库是不支持这种向量数据的,需要使用向量数据库,这里使用Milvus,同时Milvus将给这些特征向量分配一个向量ID。
- 当然你保存的时候,可以把原始的文本块和数字向量一起存储,这样可以根据数字向量反向获得原始文本。也可以将这些代表问题的ID和其对应的答案存储在关系数据库SQL Server/Postgresql中, 这一步有点类似于全文索引中给数据建索引。
当用户提出一个问题时:
- 通过OpenAI的embedding模型将之转化为特征向量
- 在Milvus中对特征向量做相似度检索,得到与该问题最相似的标准问题的id, 拿到这个数字向量后,再去自己的数据库进行检索,那么就可以得到一个结果集,这个结果集会根据匹配的相似度有个打分,分越高说明越匹配, 这样就可以按照匹配度倒序返回一个相关结果。
- 在PostgreSQL得出对应的结果集。然后根据拿到的结果集,将结果集加入到请求ChatGPT的prompt中。
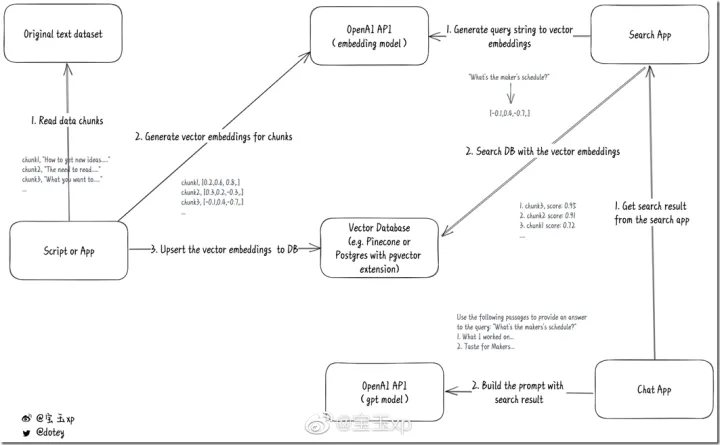
系统交互图来自宝玉的微博(https://m.weibo.cn/status/4875446737175262)如下:
参考项目地址:https://github.com/mckaywrigley/paul-graham-gpt
https://github.com/mckaywrigley/paul-graham-gptgithub.com/mckaywrigley/paul-graham-gpt
GitHub - mckaywrigley/paul-graham-gpt: AI search & chat for all of Paul Graham’s essays.
https://github.com/mckaywrigley/paul-graham-gptgithub.com/mckaywrigley/paul-graham-gpt
利用ChatGPT 和Milvus快速搭建智能问答机器人www.cnblogs.com/shanyou/p/17179348.html
3 llama-index(gpt-index)对话式文档问答解决方案
本篇介绍了类似CHATPDF这类应用的背后大致运作原理。
3.1 任务描述和问题分析
对话式文档问答,字面意思就是基于文档建立的问答系统。使用这项技术,开发者无需梳理意图、词槽,无需进行问题和答案的整理,只需准备文本格式的业务文档(例如洗碗机的使用手册),就可以得到一个问答系统,回答用户的各种问题(例如“洗碗机排水管堵塞了怎么办“)。
如果使用openai api来实现对话式文档问答,最朴素的想法把这个当成一个阅读理解问题,构建如下的prompt:
- 现有一个问题:“洗碗机排水管堵塞了怎么办”,请根据下面的文章来回答,文章内容如下:"......"
这种方法在文档较长时存在两个问题:
- 第一,openai api存在最大长度的限制,例如chatgpt的最大token数为4096,此时直接对文档截断,存在上下文丢失的问题
- 第二,api的调用费用和token长度成正比,tokens数太大,则每次调用的成本都会很高
3.2 解决思路
可以参考搜索引擎中“先检索再重排”的思路,针对文档问答设计“先检索再整合“的方案,整体思路如下:
- 首先准备好文档,并整理为纯文本的格式。把每个文档切成若干个小的chunks
- 调用文本转向量的接口,将每个chunk转为一个向量,并存入向量数据库
- 文本转向量可以使用openai embedding(https://platform.openai.com/docs/guides/embeddings/what-are-embeddings)
- 也可以使用其他方案,如fasttext/simbert等
- 当用户发来一个问题的时候,将问题同样转为向量,并检索向量数据库,得到相关性最高的一个或几个chunk
- 将问题和chunk合并重写为一个新的请求发给openai api,可能的请求格式如下:
结合下面的段落来回答问题:“ 如何使用预约功能”
* 段落1: 您可以按照以下步骤使用预约功能....
* 段落2: 在使用预约功能之前,请确保您已正确地设置了洗涤程序....
* 段落3: .......
上述“先检索再整合的逻辑”已经封装在llama-index库中
3.3 代码案例
llama-index的前身是gpt-index项目,最近才刚改名为'llama-index'。下面给出一个基于llama-index实现文档问答的具体demo,代码已上传至github:
https://github.com/xinsblog/try-llama-indexgithub.com/xinsblog/try-llama-index
一些教程案例:
参考材料:
Welcome to LlamaIndex (GPT Index)!gpt-index.readthedocs.io/en/latest/index.html
严昕:llama-index(gpt-index):后chatgpt时代的对话式文档问答解决方案178 赞同 · 62 评论文章
4 loli.xing 基于 ChatGPT 的客服系统
在 OpenAI 放出 gpt-3.5-turbo 模型之后,我们决定使用 AI 来加速目前我们重复率最高的工作:客服
按照以下方法来实现:
- 使用语雀的 API 获取我们的帮助手册及FAQ
- 获得到每篇文章后,按照 markdown 的标题进行分割,每个小标题对应一块语料.并在数据库中记录对应的网址和锚点,方便后续输出时同步给出参考文档.
- 使用 openai embeddings 获取每块语料的向量表示.
- 对用户的提问也使用 openai embeddings 提取向量.
- 使用 余弦相似度 计算用户提问和每块语料的相似度,并返回相似度最高10块的语料.
- 对每块语料按照相似度从高到低的顺序 对 token 进行求和,获取小于 2000 时的语料列表.
- 按照以下格式给与 gpt-3.5-turbo 的 system role 输入
你是 $$$ 系统的客服,请按照后续给予的使用手册回答用户的问题.
使用手册内容如下:
- 获取 gpt-3.5-turbo 的输出.
目前处于安全考虑, gpt-3.5-turbo 的输出仅发送到客服汇总群,并由客服人员进行回复.同时给与客服相关语料的标题及链接,方便客服人员进行回复.
基于 ChatGPT 的客服系统loli.xing.moe/ChatGPT_as_customer_service/
5 Document_QA
Document_QAgithub.com/fierceX/Document_QA
根据传入的文本文件,回答你的问题。
读取文件,并进行分割
- 对于每段文本,使用text-embedding-ada-002生成特征向量
- 将向量和文本对应关系存入本地pkl文件
- 对于用户输入,生成向量
- 使用向量数据库进行最近邻搜索,返回最相似的文本列表
- 使用gpt3.5的chatAPI,设计prompt,使其基于最相似的文本列表进行回答
就是先把大量文本中提取相关内容,再进行回答,最终可以达到类似突破token限制的效果
后续可以考虑将openai的文本向量改成自定义的向量生成工具
6 ChatWeb
ChatWeb可以爬取任意网页并提取正文,生成概要,然后根据正文内容回答你的问题。 目前是个原理展示的Demo,还没有细分逻辑。 基于gpt3.5的chatAPI和embeddingAPI,配合向量数据库。
https://github.com/SkywalkerDarren/chatWebgithub.com/SkywalkerDarren/chatWeb
基本类似于现有的chatPDF,自动化客服AI等项目的原理。
- 爬取网页
- 提取正文
- 对于每一段落,使用gpt3.5的embeddingAPI生成向量
- 每一段落的向量和全文向量做计算,生成概要
- 将向量和文本对应关系存入向量数据库
- 对于用户输入,生成向量
- 使用向量数据库进行最近邻搜索,返回最相似的文本列表
- 使用gpt3.5的chatAPI,设计prompt,使其基于最相似的文本列表进行回答
就是先把大量文本中提取相关内容,再进行回答,最终可以达到类似突破token限制的效果
7 chatpdf-minimal-demo
https://github.com/postor/chatpdf-minimal-demogithub.com/postor/chatpdf-minimal-demo
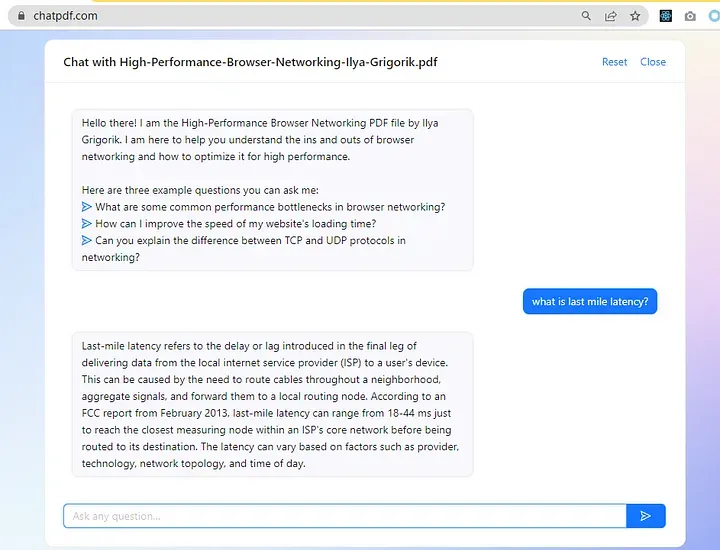
实现原理 | process flow
- 文章切片到段落 | split articles into pieces
- 通过 OpenAI 的 embedding 接口将每个段落转换为 embedding | convert each piece into embedding with OpenAI
- 将提问的问题转换为 embedding | convert user question into embedding
- 把问题的 embedding 比较所有段落 embedding 得到近似程度并排序 | compare question embedding with all the embeddings of pieces and sort the result
- 把和提问(语义)最接近的一个或几个段落作为上下文,通过 OpenAI 的对话接口得到最终的答案 | use the nearest (meaning) piece(s) as context and ask ChatGPT for the final answer
几个核心代码片段:
获取embedding:
import openai
def get_embedding(text: str, model: str=EMBEDDING_MODEL) -> list[float]:
result = openai.Embedding.create(
model=model,
input=text
)
return result["data"][0]["embedding"]
用户问题排序:
def order_document_sections_by_query_similarity(query: str, embeddings) -> list[(float, (str, str))]:
#pprint.pprint("embeddings")
#pprint.pprint(embeddings)
"""
Find the query embedding for the supplied query, and compare it against all of the pre-calculated document embeddings
to find the most relevant sections.
Return the list of document sections, sorted by relevance in descending order.
"""
query_embedding = get_embedding(query)
document_similarities = sorted([
(vector_similarity(query_embedding, doc_embedding), doc_index) for doc_index, doc_embedding in enumerate(embeddings)
], reverse=True, key=lambda x: x[0])
return document_similarities
当问题被问到时,获取最近的信息作为上下文并询问 ChatGPT:
def ask(question:str,embeddings,sources):
ordered_candidates = order_document_sections_by_query_similarity(question,embeddings)
ctx = ""
for candi in ordered_candidates:
next = ctx + " " + sources[candi[1]]
if len(next)>CONTEXT_TOKEN_LIMIT:
break
ctx = next
if len(ctx) == 0:
return ""
prompt = "".join([
u"Answer the question based on the following context:\n\n"
u"context:"+ ctx +u"\n\n"
u"Q:"+question+u"\n\n"
u"A:"
])
completion = openai.ChatCompletion.create(model="gpt-3.5-turbo", messages=[{"role": "user", "content":prompt}])
return [prompt, completion.choices[0].message.content]
一个网页版图例:
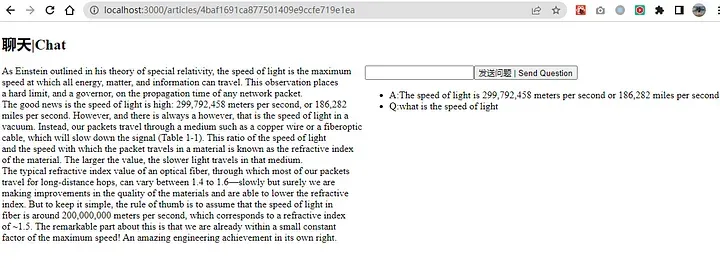
screenshot of postor/chatpdf-minimal-demo
8 llama_index建立个人知识库的GPT问答
僵尸浩:【GPT】llama_index(一)快速建立个人知识库的GPT问答38 赞同 · 8 评论文章
僵尸浩:【GPT】llama_index(二)使用踩坑 —— 在chatgpt-plugin之前我们就已经可以plugin了60 赞同 · 23 评论文章
僵尸浩:【GPT】llama_index(三)改用langchain+向量数据库,灵活实现GPT外部数据检索33 赞同 · 1 评论文章
llama_index库是一个项目,它提供了一个中心接口,可以将您的语言模型(LLM)与外部数据连接起来[2]。它提供了一组数据结构,可以为各种LLM任务索引大量数据,并消除了关于提示大小限制和数据摄入的问题[1]。它还支持与LangChain和LlamaHub等其他工具或库的集成
langchain的向量搜索
尽管llama_index是基于langchain开发的,但向量搜索这件事本来也被OpenAI官方吸收了,向量数据库也成熟了那么多年。langchain有什么理由不整合呢?毕竟langchain是拿了高额的投资的,自然不会放弃扩张自己版图的机会。
所以,langchain也有自己的index模块和vectorstore对象。其设计和retrieval-plugin的思路比较像 ———— 接入第三方的向量数据库。而且这俩模块专注于完成向量搜索,你输入一个问句,它只会将相关的参考文档返回给你。并不急于做后续的GPT请求。这样你就可以在发GPT请求之前添加许多自己的逻辑了。
9 ChatGLM-6B+langchain实现的基于本地知识的 ChatGLM 应用
https://github.com/imClumsyPanda/langchain-ChatGLMgithub.com/imClumsyPanda/langchain-ChatGLM
受 GanymedeNil 的项目 document.ai 和 AlexZhangji 创建的 ChatGLM-6B Pull Request 启发,建立了全部基于开源模型实现的本地知识问答应用。
✅ 本项目中 Embedding 默认选用的是 GanymedeNil/text2vec-large-chinese,LLM 默认选用的是 ChatGLM-6B。依托上述模型,本项目可实现全部使用开源模型 离线私有部署 。
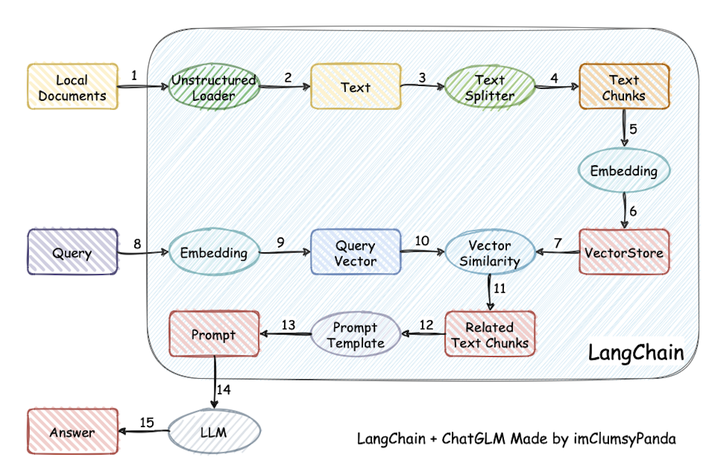
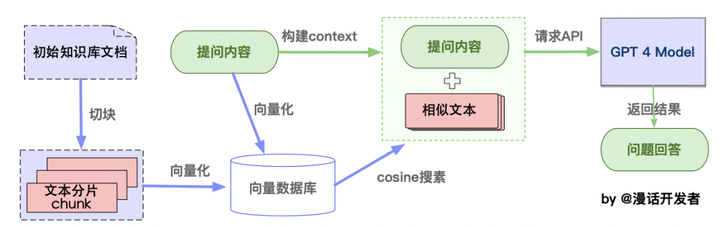
⛓️ 本项目实现原理如下图所示,过程包括加载文件 -> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 -> 在文本向量中匹配出与问句向量最相似的top k个 -> 匹配出的文本作为上下文和问题一起添加到prompt中 -> 提交给LLM生成回答。
10 基于ChatGLM-6b+langchain实现本地化知识库检索与智能答案生成
https://github.com/yanqiangmiffy/Chinese-LangChaingithub.com/yanqiangmiffy/Chinese-LangChain
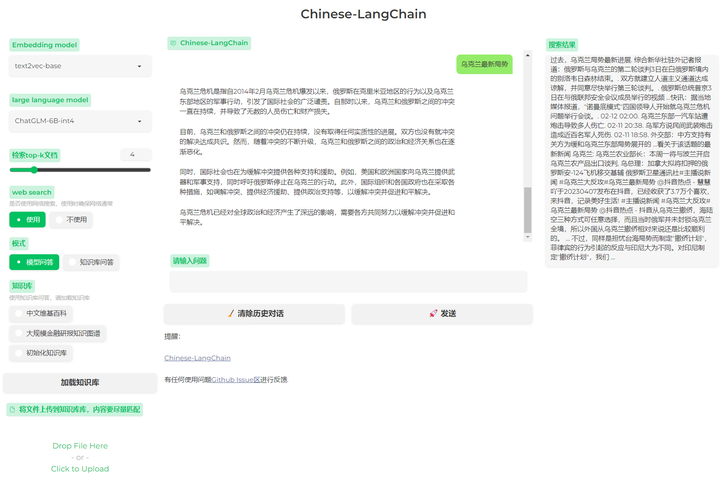
已经有很多更新:
- 2023/04/22 支持模型多机多卡推理
- 2023/04/20 支持模型问答与检索问答模式切换
- 2023/04/20 感谢HF官方提供免费算力,添加HuggingFace Spaces在线体验[DEMO
- 2023/04/19 发布45万Wikipedia的文本预处理语料以及FAISS索引向量
- 2023/04/19 引入ChuanhuChatGPT皮肤
- 2023/04/19 增加web search功能,需要确保网络畅通!(感谢@wanghao07456,提供的idea)
- 2023/04/18 webui增加知识库选择功能
- 2023/04/18 修复推理预测超时5s报错问题
- 2023/04/17 支持多种文档上传与内容解析:pdf、docx,ppt等
- 2023/04/17 支持知识增量更新
11 快速小程序搭一个问答机器人
漫话开发者:如何用低代码搭建训练一个专业知识库问答GPT机器人15 赞同 · 4 评论文章
目前的预训练方式主要如下几种:
- 基于OpenAI的官方LLM模型,进行 fine-tune[1] (费用高,耗时长)
- 基于开源的 Alpaca.cpp[2] 本地模型(目前可在本地消费级显卡跑起来,对自己硬件有信心也可以试试)
- 通过向量数据库上下文关联(轻量级,费用可控,速度快,包括昨天OPENAI官方昨天刚放出来的示例插件 chatgpt-retrieval-plugin[3] ,也采用的这种方式)
低代码实现的AI问答机器人效果如下:
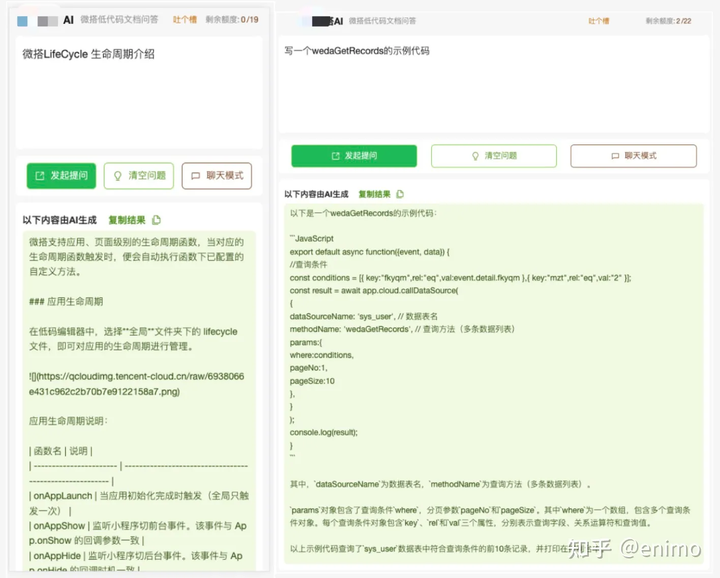
在开始搭建垂直知识库的问答机器人前,你需要做以下准备:
- 微信小程序账号:如果您还没有微信小程序账号,可以在微信公众平台注册(如果没有小程序,也可以发布为移动端H5应用)
- 开通腾讯云微搭低代码:微搭低代码是腾讯云官方推出的一款低代码开发工具,可以直接访问 腾讯云微搭官网[4] 免费开通注册
- OpenAI账号:OpenAI账号注册也是免费的,不过OpenAI有地域限制,网上方法很多在此不赘述。注册成功后,可以登录OpenAI的 个人中心[5] 来获取
API KEY - 一个支持向量匹配的数据库(本文以开源的
PostgreSQL为例,你也可以使用Redis,或者NPM的HNSWlib包)
关于向量数据库,目前可选择的方式有好几种,可以使用PostgreSQL安装vector向量扩展,也可以使用Redis的 Vector Similarity Search[6] ,还可以直接云函数使用HNSWLib库,甚至自行diy一个简单的基于文件系统的余弦相似度向量数据库,文末的 github/lowcode.ai 也有简单示例代码,仅做参考交流不建议在生产环境使用。
本教程适用人群和应用类型:
- 适用人群:有前后端基础的开发者(有一定技术背景的非开发者也可以体验)
- 应用类型:小程序 或 H5应用(基于微搭一码多端特性,可以发布为Web应用,点击原文链接可体验作者基于微搭搭建的 文档GPT机器人[7] )
转自 https://zhuanlan.zhihu.com/p/614334596
标题:想自己利用OpenAI做一个文档问答的知识库
作者:michael
地址:https://blog.junxworks.cn/articles/2023/04/27/1682566952994.html