MySQL的查询需要遍历几次B+树,理论上需要几次磁盘I/O?
一、前言 加油
二、遍历B+树的次数 首先,既然问题是一次查询,那我们肯定是要知道mysql使用的存储引擎是哪个,要根据存储引擎的不同判断索引的结构,然后通过索引的B+树来回答这些问题。 MySQL中MyISAM和InnoDB的索引方式以及区别与选择
1、mysql的innodb引擎的聚集索引和非聚集索引 网上看到很多资料,有的叫innodb的索引为聚集索引,有的叫做聚簇索引,其实都是一样的,只是在翻译过来了时候命名产生了分歧,聚簇(集)索引的叶子节点就是数据节点,而非聚簇(集)索引的叶子节点仍然是索引节点,只不过有指向对应数据块的指针。非聚簇(集)索引在innodb引擎中,又叫做二级索引,辅助索引等。
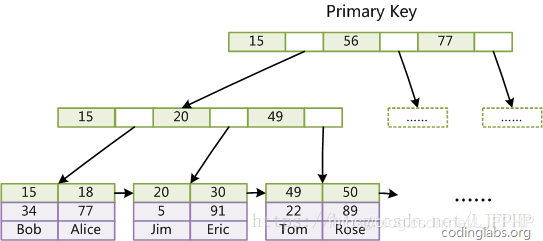
2、分别遍历了几次B+树 主键索引从上至下遍历一次B+树,直到找到具体的主键,拿到叶子结点存储的数据。 二级索引需要遍历两次B+树,第一次遍历是找到对应的主键,第二次遍历是根据主键找到具体的数据。
比如查询二级索引的sql,先通过遍历二级索引的B+树来找到对应的主键,然后回表即通过主键遍历聚集索引B+树,拿到具体的数据。(PS:mysql里面每次新建索引都会生成新的B+树,这也是索引文件会随着索引字段不断增加的原因)
这部分是要参照索引的图来的,如图:
(1)主键索引(聚集索引)
(2)辅助索引(二级索引)
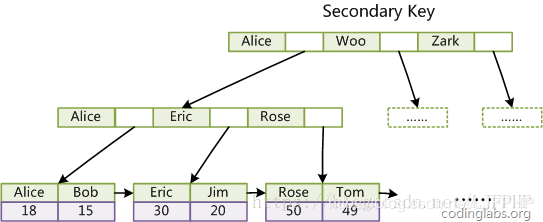
3、回表的概念 回表就是通过辅助索引拿到主键id之后,要再去遍历聚集索引的B+树,这个过程就叫做回表。回表的操作更多的是随机io,随机io在性能上还是比较低下的,例如:
- 比如user表中有三个字段,a,b,c,给a和b建立联合索引idex_a_b(a,b) sql:select * from user where a=1 and b=2; (1)首先是用二级索引index_a_b来查询,速度会很快。(顺序IO) (2)拿到主键id之后,这个主键id并不是顺序排列的,还要用主键去查询聚簇索引(随机io) (3)当随机io很多,也就是拿到的主键id很多的时候,回表的代价是巨大的。所以最好是选用覆盖索引或者让where 之后的条件筛选更多的数据
三、聚集索引和非聚集索引执行一次sql的io次数 1、聚集索引
大致步骤如下:
(1) 数据量小的话,直接把索引放到内存中,内存的O(logn)消耗是远远低于磁盘io的,所以可以忽略不计 (2) 数据量大的话,采用索引结构,我们这部分先从二叉树说起,对于普通二叉树,第一个步骤是二分,每次判断都是一次半数的数量级检索。假如有100W的数据,大概的时间复杂度是:log2N=1000000即N=20的节点获取,也就是磁盘I/O复杂度最大为O(20),二分的时间复杂度是O(log2N)。 (3) 但是对于数据库来说,存储场景会更加复杂,二叉树的性能虽然好,但我们还是想要树的高度更低一些,存储的数据更多一些。因此mysql引入了B+树的概念。除了根节点之外,第二层级的数量得到了充分的扩展,相对于普通的二叉树,B+树的结构更加庞大又不失美感,假设叶节点不同元素占用情况为:左右指针各占4Byte,id值8Byte,目标记录指针4Byte,那么一个4Kb的磁盘块将大致可以容纳250个下级指针,100万行目标记录只需log250N=1000000即N=3的I/O次数,充分提升了每次节点I/O带来的检索效用,时间复杂度是O(lognN),这里的n是非叶子结点的个数。(PS:实际上innodb的数据页大小是16kb,这个n会更大,那么对应的,io次数也会更少) (4) 在实际的查询中,IO次数可能会更小,因为有可能会把部分用到的索引读取到内存中,相对于磁盘IO来说,内存的io消耗可以忽略不计。一般来说B+Tree的高度一般都在2-4层,MySQL的InnoDB存储引擎在设计时是将根节点常驻内存的,也就是说查找某一键值的行记录时最多只需要1~3次磁盘I/O操作(根节点的那次不算磁盘I/O)。
关于二分,我们假设有50W数据,下面看一下效果
1 50W 2 25W 3 12.5W 4 6W 5 3W 6 1.5W 7 7000 8 3500 9 1800 //第9次的时候,数据范围就已经很小了,当然,它的效率还不够高,但是比遍历所有数据要快多了 根据以上的解释,我们可以知道聚集索引的磁盘IO次数大概是1-3次,这一切都是因为高效的B+树。如果大家也碰到类似的问题,就照着上面一顿胡扯,绝对很稳了。
2、辅助索引
(1) 参考上面对于B+树的解释,辅助索引获取主键的时间复杂度是 lognN(假设第二层级是n个节点) (2) 再通过lognN获取主键对应的数据列 参考 io解释 四、引申问题 在进行相关测试的时候,可能会因为一部分索引放到了内存,从而造成一定的误差。因此咱们这边就来探讨探讨,这个放进内存的索引有多大。
1、多大的索引数据可以放到内存中?
(1) 要参照自己的mysql设置,一般是innodb_buffer_pool_size的值,这个值默认是128M,具体的要根据机器的性能设置。
关于Innodb_buffer_pool_size:《深入浅出MySQL》一文中这样描述Innodb_buffer_pool_size:
该参数定义了 InnoDB 存储引擎的表数据和索引数据的最大内存缓冲区大小。和 MyISAM 存储引擎不同,
MyISAM 的 key_buffer_size只缓存索引键, 而 innodb_buffer_pool_size 却是同时为数据块和索引块做缓存,
这个特性和 Oracle 是一样的。这个值设得越高,访问 表中数据需要的磁盘 I/O 就越少。在一个专用的数据库
服务器上,可以设置这个参数达机器 物理内存大小的 80%。尽管如此,还是建议用户不要把它设置得太大,
因为对物理内存的竞 争可能在操作系统上导致内存调度。
(2) 内存缓冲区主要包含 上面第一条提到的内存缓冲区主要包括:数据缓存(innodb的行数据),索引数据,缓冲数据(在内存中修改尚未刷新(写入)到磁盘的数据),内部结构(自适应哈希索引,行锁等。)
(3) 所以说,放到内存中的索引大小,和这些配置息息相关,当索引在内存中的时候,自然是用不到磁盘io的
具体参考: 如何在MySQL中分配innodb_buffer_pool_size
2、mysql一次普通查询经过的步骤 从查询过程上看,大致步骤是:
查看缓存中是否存在id,
如果有 则从内存中访问,否则要访问磁盘,
并将索引数据存入内存,利用索引来访问数据,
对于数据也会检查数据是否存在于内存,
如果没有则访问磁盘获取数据,读入内存。
返回结果给用户。
据实际的情况分析。
五、总结 写完博客之后,越发感觉到自己的才疏学浅。对于mysql来说,这些本来就都是基础知识,但我到现在才算明白了一点点。而且这一点点也许还不够准确,实在是让人绝望呢。翻看mysql的手册,上面有很多介绍,也有很多配置项都没有用过,各位且学且珍惜吧
标题:MySQL的查询需要遍历几次B+树,理论上需要几次磁盘I/O?
作者:michael
地址:https://blog.junxworks.cn/articles/2022/11/27/1669541673808.html