ShardingSphere 归并
前言
ShardingSphere结果归并根据sql情况不同分为以下几种类型:
- 遍历归并:也就是普通的归并,直接归并所有结果集
- 排序归并:针对order by的查询语句最后的结果归并
- 分组归并:针对group by的查询语句最后的结果归并
- 分页归并:针对limit分页的查询语句最后的结果归并
- 聚合归并:针对min、max、sum、count、avg聚合函数的查询语句最后的结果归并
其设计图如下:
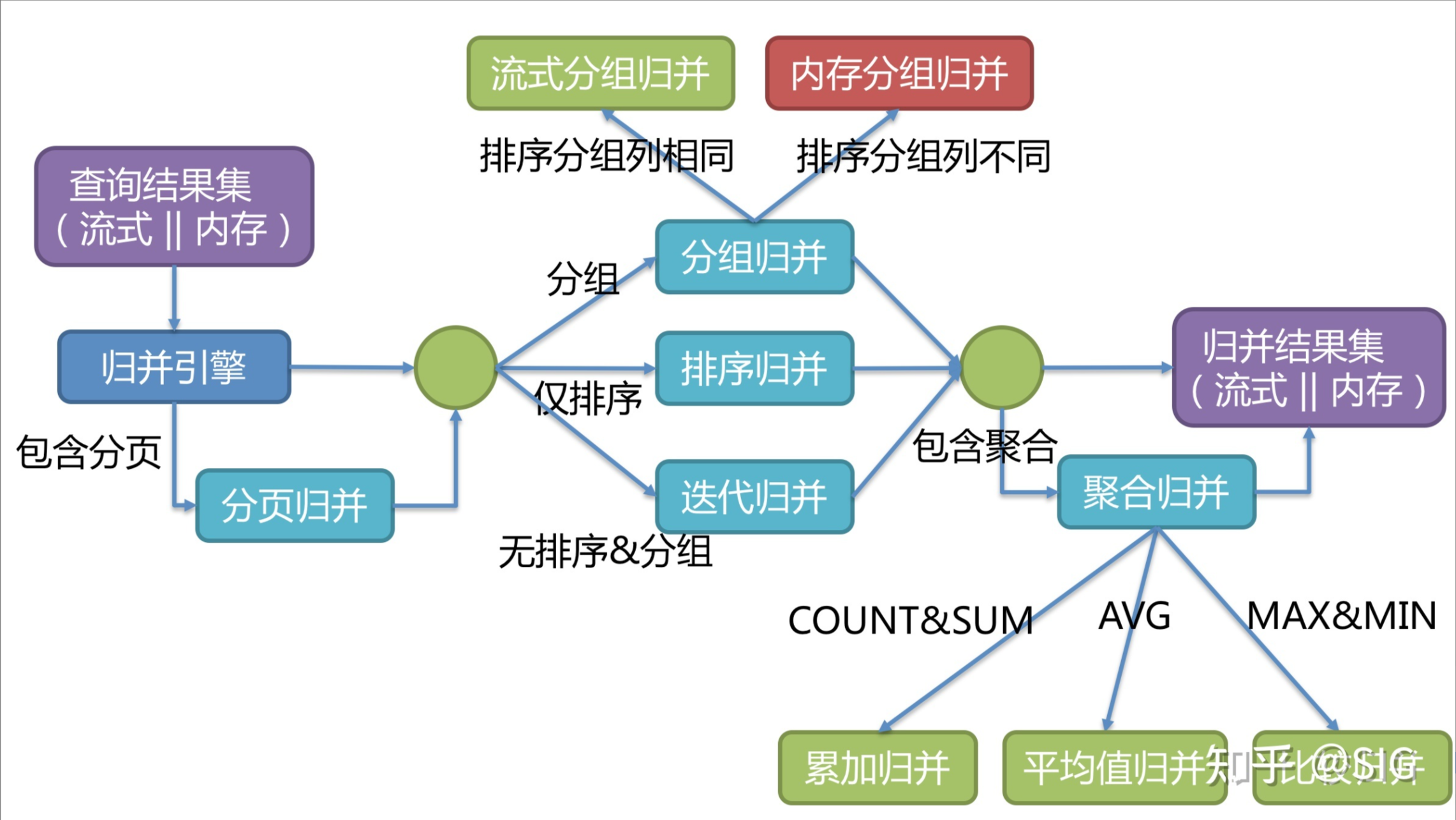
当然底层也有流式归并和内存归并划分,详细可看上一篇ShardingSphere执行文章
下面我们就来看一下ShardingSphere对这些归并的处理
我们以ShardingSpherePreparedStatement#mergeQuery方法进行入口分析
1、ShardingSpherePreparedStatement#mergeQuery
public final class ShardingSpherePreparedStatement extends AbstractPreparedStatementAdapter {
/**
* 合并查询结果
* @param queryResults 执行返回结果集
* @return 合并后的结果
*/
private MergedResult mergeQuery(final List<QueryResult> queryResults) throws SQLException {
ShardingSphereMetaData metaData = metaDataContexts.getDefaultMetaData();
//创建归并引擎
MergeEngine mergeEngine = new MergeEngine(
metaDataContexts.getDefaultMetaData().getResource().getDatabaseType(), metaData.getSchema(), metaDataContexts.getProps(), metaData.getRuleMetaData().getRules());
//调用归并引擎的merge方法
return mergeEngine.merge(queryResults, executionContext.getSqlStatementContext());
}
}
可以看到,就是创建归并引擎,调用引擎的归并方法
下面我们来看一下执行引擎的代码
2、MergeEngine
public final class MergeEngine {
static {
//SPI 加载ResultProcessEngine类
ShardingSphereServiceLoader.register(ResultProcessEngine.class);
}
private final Map<ShardingSphereRule, ResultProcessEngine> engines;
public MergeEngine(final DatabaseType databaseType, final ShardingSphereSchema schema, final ConfigurationProperties props, final Collection<ShardingSphereRule> rules) {
this.databaseType = databaseType;
this.schema = schema;
this.props = props;
//所有SPI ResultProcessEngine实现类
engines = OrderedSPIRegistry.getRegisteredServices(rules, ResultProcessEngine.class);
}
/**
* Merge.
*
* @param queryResults query results
* @param sqlStatementContext SQL statement context
* @return merged result
* @throws SQLException SQL exception
*/
public MergedResult merge(final List<QueryResult> queryResults, final SQLStatementContext<?> sqlStatementContext) throws SQLException {
//归并后的结果
Optional<MergedResult> mergedResult = executeMerge(queryResults, sqlStatementContext);
//如果归并后的结果不为空,则调用decorate选择进一步装饰,否则直接取执行结果集的第一位进行进一步装饰
Optional<MergedResult> result = mergedResult.isPresent() ? Optional.of(decorate(mergedResult.get(), sqlStatementContext)) : decorate(queryResults.get(0), sqlStatementContext);
//如果装饰后的结果为空,则直接取执行结果集的第一位
return result.orElseGet(() -> new TransparentMergedResult(queryResults.get(0)));
}
@SuppressWarnings({"unchecked", "rawtypes"})
private Optional<MergedResult> executeMerge(final List<QueryResult> queryResults, final SQLStatementContext<?> sqlStatementContext) throws SQLException {
//遍历SPI注册的所有结果处理引擎ResultProcessEngine
for (Entry<ShardingSphereRule, ResultProcessEngine> entry : engines.entrySet()) {
//如果是结果归并引擎则执行
if (entry.getValue() instanceof ResultMergerEngine) {
//结果处理引擎创建ResultMerger实例,会根据sqlStatementContext类型创建不同的ResultMerger子类对象
ResultMerger resultMerger = ((ResultMergerEngine) entry.getValue()).newInstance(databaseType, entry.getKey(), props, sqlStatementContext);
//调用ResultMerger的merge方法
return Optional.of(resultMerger.merge(queryResults, sqlStatementContext, schema));
}
}
return Optional.empty();
}
}
可以看到这里有一个SPI扩展接口,结果处理引擎ResultProcessEngine,同时ShardingSphere还设计了一个装饰器装饰合并结果的扩展点
该扩展点需要ResultProcessEngine实现类实现ResultDecoratorEngine接口
总得来说,MergeEngine主要靠调用ResultProcessEngine实现类来创建一个ResultMerger,进而使用ResultMerger的merge方法进行结果归并
我们接下来就来看一下ShardingSphere自带的分片的结果处理引擎ShardingResultMergerEngine创建的针对查询语句的ShardingDQLResultMerger
3、ShardingDQLResultMerger
@RequiredArgsConstructor
public final class ShardingDQLResultMerger implements ResultMerger {
@Override
public MergedResult merge(final List<QueryResult> queryResults, final SQLStatementContext<?> sqlStatementContext, final ShardingSphereSchema schema) throws SQLException {
if (1 == queryResults.size()) {
//如果执行结果集里面只有一个结果,直接包装成流式归并结果返回
return new IteratorStreamMergedResult(queryResults);
}
//构建结果集的列名和下标map
Map<String, Integer> columnLabelIndexMap = getColumnLabelIndexMap(queryResults.get(0));
SelectStatementContext selectStatementContext = (SelectStatementContext) sqlStatementContext;
//保存列名-下标map到SelectStatementContext
selectStatementContext.setIndexes(columnLabelIndexMap);
//构建归并结果
MergedResult mergedResult = build(queryResults, selectStatementContext, columnLabelIndexMap, schema);
//分页归并装饰器
return decorate(queryResults, selectStatementContext, mergedResult);
}
private Map<String, Integer> getColumnLabelIndexMap(final QueryResult queryResult) throws SQLException {
Map<String, Integer> result = new TreeMap<>(String.CASE_INSENSITIVE_ORDER);
for (int i = queryResult.getMetaData().getColumnCount(); i > 0; i--) {
result.put(SQLUtil.getExactlyValue(queryResult.getMetaData().getColumnLabel(i)), i);
}
return result;
}
private MergedResult build(final List<QueryResult> queryResults, final SelectStatementContext selectStatementContext,
final Map<String, Integer> columnLabelIndexMap, final ShardingSphereSchema schema) throws SQLException {
//select语句有group by分组 或 聚合函数sum、avg这些都
if (isNeedProcessGroupBy(selectStatementContext)) {
return getGroupByMergedResult(queryResults, selectStatementContext, columnLabelIndexMap, schema);
}
//select语句有去重distinct
if (isNeedProcessDistinctRow(selectStatementContext)) {
setGroupByForDistinctRow(selectStatementContext);
return getGroupByMergedResult(queryResults, selectStatementContext, columnLabelIndexMap, schema);
}
//select语句有order by排序
if (isNeedProcessOrderBy(selectStatementContext)) {
return new OrderByStreamMergedResult(queryResults, selectStatementContext, schema);
}
//普通遍历归并
return new IteratorStreamMergedResult(queryResults);
}
private MergedResult getGroupByMergedResult(final List<QueryResult> queryResults, final SelectStatementContext selectStatementContext,
final Map<String, Integer> columnLabelIndexMap, final ShardingSphereSchema schema) throws SQLException {
//如果group by的字段和order by的字段相同,则使用流式归并,否则使用内存归并
return selectStatementContext.isSameGroupByAndOrderByItems()
? new GroupByStreamMergedResult(columnLabelIndexMap, queryResults, selectStatementContext, schema)
: new GroupByMemoryMergedResult(queryResults, selectStatementContext, schema);
}
}
在这里已经可以很清楚的看到前言里面列举的各种归并类型:
- 遍历归并:也就是普通的归并,直接归并所有结果集
- 排序归并:针对order by的查询语句最后的结果归并
- 分组归并:针对group by的查询语句最后的结果归并
- 聚合归并:针对min、max、sum、count、avg聚合函数的查询语句最后的结果归并
- 分页归并:针对limit分页的查询语句最后的结果归并,上面的所有类型也都可能是分页归并类型,它们不是互斥关系
在这里我们就选择分组归并和聚合归并来看一下代码
4、GroupByStreamMergedResult
public final class GroupByStreamMergedResult extends OrderByStreamMergedResult {
private final SelectStatementContext selectStatementContext;
private final List<Object> currentRow;
private List<?> currentGroupByValues;
public GroupByStreamMergedResult(final Map<String, Integer> labelAndIndexMap, final List<QueryResult> queryResults,
final SelectStatementContext selectStatementContext, final ShardingSphereSchema schema) throws SQLException {
//这里会进行优先队列数据初始化,优先队列定义在OrderByStreamMergedResult
super(queryResults, selectStatementContext, schema);
this.selectStatementContext = selectStatementContext;
//currentRow可以存一行数据
currentRow = new ArrayList<>(labelAndIndexMap.size());
currentGroupByValues = getOrderByValuesQueue().isEmpty()
? Collections.emptyList() : new GroupByValue(getCurrentQueryResult(), selectStatementContext.getGroupByContext().getItems()).getGroupValues();
}
@Override
public boolean next() throws SQLException {
currentRow.clear();
//优先队列为空,证明没有下一位元素
if (getOrderByValuesQueue().isEmpty()) {
return false;
}
if (isFirstNext()) {
super.next();
}
if (aggregateCurrentGroupByRowAndNext()) {
currentGroupByValues = new GroupByValue(getCurrentQueryResult(), selectStatementContext.getGroupByContext().getItems()).getGroupValues();
}
return true;
}
private boolean aggregateCurrentGroupByRowAndNext() throws SQLException {
boolean result = false;
boolean cachedRow = false;
//聚和函数->AggregationUnit (MAX、MIN、SUM、COUNT、AVG)
Map<AggregationProjection, AggregationUnit> aggregationUnitMap = Maps.toMap(
selectStatementContext.getProjectionsContext().getAggregationProjections(), input -> AggregationUnitFactory.create(input.getType(), input instanceof AggregationDistinctProjection));
//getCurrentQueryResult() 优先队列会出队,然后判断是否是同一组
while (currentGroupByValues.equals(new GroupByValue(getCurrentQueryResult(), selectStatementContext.getGroupByContext().getItems()).getGroupValues())) {
//归并聚和函数的值
aggregate(aggregationUnitMap);
if (!cachedRow) {
//存储结果到currentRow
cacheCurrentRow();
cachedRow = true;
}
//下一个结果,优先队列会出队
result = super.next();
if (!result) {
break;
}
}
//currentRow设置聚和函数值
setAggregationValueToCurrentRow(aggregationUnitMap);
return result;
}
private void aggregate(final Map<AggregationProjection, AggregationUnit> aggregationUnitMap) throws SQLException {
for (Entry<AggregationProjection, AggregationUnit> entry : aggregationUnitMap.entrySet()) {
//count、sum...
List<Comparable<?>> values = new ArrayList<>(2);
if (entry.getKey().getDerivedAggregationProjections().isEmpty()) {
values.add(getAggregationValue(entry.getKey()));
} else {
for (AggregationProjection each : entry.getKey().getDerivedAggregationProjections()) {
//拿到聚和函数计算值
values.add(getAggregationValue(each));
}
}
//调用AggregationUnit的merge方法即可对和合函数进行归并
entry.getValue().merge(values);
}
}
}
这里会涉及到一个优先队列的设计
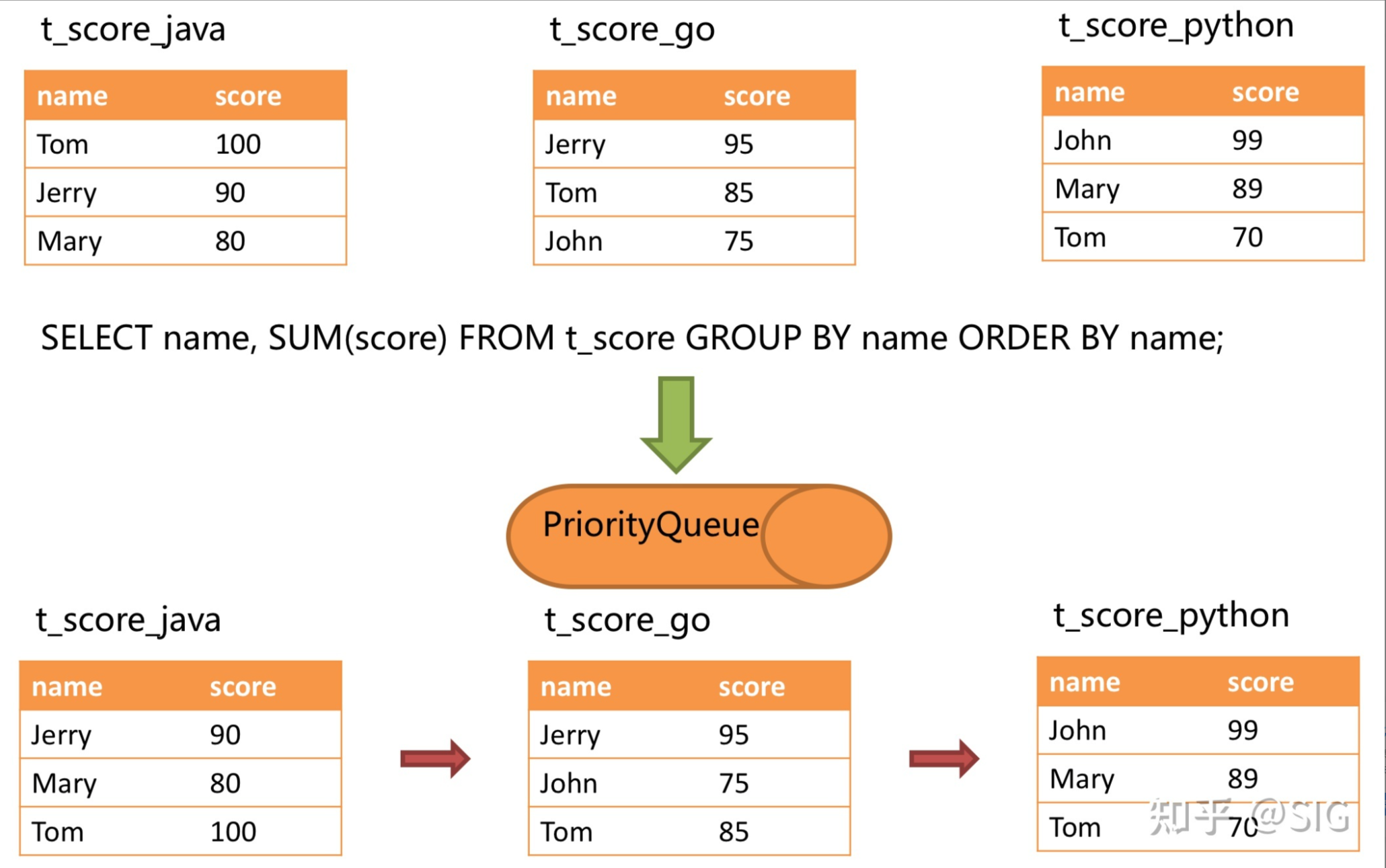
ShardingSphere会把结果集按照order by的比较规则,放到优先队列里面,每次取堆顶元素,并进行分组、聚合函数归并再重新放到结果里面等
接下来我们看一下优先队列的定义、初始化、比较规则,在OrderByStreamMergedResult类里面
5、OrderByStreamMergedResult
public class OrderByStreamMergedResult extends StreamMergedResult {
private final Collection<OrderByItem> orderByItems;
@Getter(AccessLevel.PROTECTED)
private final Queue<OrderByValue> orderByValuesQueue;
@Getter(AccessLevel.PROTECTED)
private boolean isFirstNext;
public OrderByStreamMergedResult(final List<QueryResult> queryResults, final SelectStatementContext selectStatementContext, final ShardingSphereSchema schema) throws SQLException {
orderByItems = selectStatementContext.getOrderByContext().getItems();
orderByValuesQueue = new PriorityQueue<>(queryResults.size());
//把数据放到优先队列里面
orderResultSetsToQueue(queryResults, selectStatementContext, schema);
isFirstNext = true;
}
private void orderResultSetsToQueue(final List<QueryResult> queryResults, final SelectStatementContext selectStatementContext, final ShardingSphereSchema schema) throws SQLException {
for (QueryResult each : queryResults) {
//把结果集构造成OrderByValue,进行结果排序
OrderByValue orderByValue = new OrderByValue(each, orderByItems, selectStatementContext, schema);
if (orderByValue.next()) {
orderByValuesQueue.offer(orderByValue);
}
}
setCurrentQueryResult(orderByValuesQueue.isEmpty() ? queryResults.get(0) : orderByValuesQueue.peek().getQueryResult());
}
@Override
public boolean next() throws SQLException {
if (orderByValuesQueue.isEmpty()) {
return false;
}
if (isFirstNext) {
isFirstNext = false;
return true;
}
//出队
OrderByValue firstOrderByValue = orderByValuesQueue.poll();
//如果结果集还没取完,下一位入队
if (firstOrderByValue.next()) {
orderByValuesQueue.offer(firstOrderByValue);
}
if (orderByValuesQueue.isEmpty()) {
return false;
}
//设置当前所读结果集为优先队列堆顶元素
setCurrentQueryResult(orderByValuesQueue.peek().getQueryResult());
return true;
}
}
可以看到,这里是把OrderByValue对象放到优先队列里面,我们来看一下OrderByValue对Comparable的实现
public final class OrderByValue implements Comparable<OrderByValue> {
public OrderByValue(final QueryResult queryResult, final Collection<OrderByItem> orderByItems,
final SelectStatementContext selectStatementContext, final ShardingSphereSchema schema) throws SQLException {
this.queryResult = queryResult;
this.orderByItems = orderByItems;
orderValuesCaseSensitive = getOrderValuesCaseSensitive(selectStatementContext, schema);
}
@Override
public int compareTo(final OrderByValue o) {
int i = 0;
for (OrderByItem each : orderByItems) {
//针对order by的每一项进行比较,ASC还是DESC是在CompareUtil.compareTo有区分
int result = CompareUtil.compareTo(orderValues.get(i), o.orderValues.get(i), each.getSegment().getOrderDirection(),
each.getSegment().getNullOrderDirection(), orderValuesCaseSensitive.get(i));
if (0 != result) {
return result;
}
i++;
}
return 0;
}
}
就是按order by规则排序的。
转载自 https://zhuanlan.zhihu.com/p/406678998
参考 https://shardingsphere.apache.org/document/4.1.1/cn/features/sharding/principle/merge/