ShardingSphere基于junx-shardingsphere-datamigrate+shardingsphere-proxy做单/多表数据迁移
介绍
目前ShardingSphere做分库分表很流行,而且是国人开源的数据库中间件,值得我们去发扬光大。但是做分库分表难免会遇到数据库扩展,要进行数据迁移的问题,ShardingSphere本身提供了Sharding-Scaling用于全库全量+增量的方式进行主库与扩展库的同步,但是痛点在与Sharding-Scaling是全库同步,你必须准备两套数据库环境,有点浪费资源,而且万一你仅仅是想把原数据库中的某几个表做分表操作,采用Sharding-Scaling是杀鸡用牛刀,不合适。因此开发了轻量级数据迁移工具junx-shardingsphere-datamigrate,用于shardingsphere做部分表全量数据迁移(非增量)。
junx-shardingsphere-datamigrate源码参见:https://gitee.com/junxworks/junx-shardingsphere-datamigrate
datamigrate数据抽取逻辑
junx-shardingsphere-datamigrate目前以功能简单直接为主,就是从指定的源库抽取数据,发往具有新分库分表逻辑的ShardingSphere-proxy代理,由sharding代理来执行新的数据分片逻辑,数据抽取大致逻辑如下,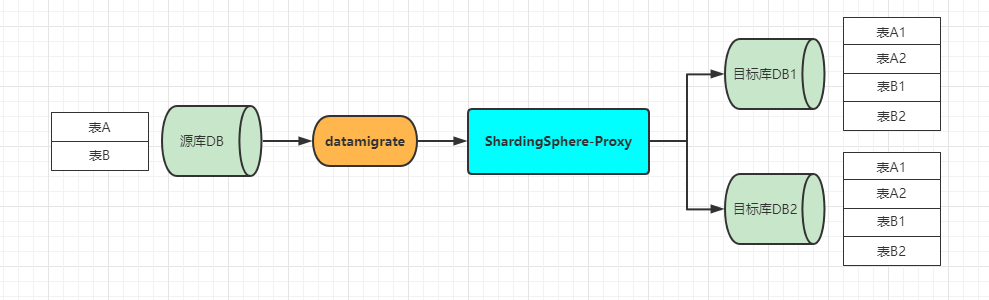
目前junx-shardingsphere-datamigrate仅支持从单一源库抽取指定的表发送到ShardingSphere-proxy代理,如果源库已经是分库,那么需要同时启动多个junx-shardingsphere-datamigrate进程来抽取多个库的数据。
使用
junx-shardingsphere-datamigrate是基于springboot2.5.5开发,是一个标准的springboot web应用,内部有数据迁移引擎,实现了多数据源之间的数据同步功能,因此junx-shardingsphere-datamigrate的启动与普通的springboot web应用启动是一样的,通过jar包的方式启动,有已经打包好的程序,在/dist目录,下载下来修改配置文件后即可运行。
把整个dist目录拷贝出来,编辑其中的start文件,windows是编辑start.bat文件,linux编辑start.sh。其中默认参数只有源数据库与目标数据库两个数据源的配置以及需要从源数据库中抽取的表列表,具体启动命令行如下:
java -Xmx4G -Xms4G -jar junx-shardingsphere-datamigrate-1.1.0.jar
--spring.profiles.active=pro
--spring.datasource.druid.primary.url="jdbc:mysql://ip:port/dbname?serverTimezone=Asia/Shanghai&allowMultiQueries=true&useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&rewriteBatchedStatements=true&zeroDateTimeBehavior=convertToNull"
--spring.datasource.druid.primary.username="xxx"
--spring.datasource.druid.primary.password="xxx"
--spring.datasource.druid.target.url="jdbc:mysql://ip:port/dbname?serverTimezone=Asia/Shanghai&allowMultiQueries=true&useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&rewriteBatchedStatements=true&zeroDateTimeBehavior=convertToNull"
--spring.datasource.druid.target.username="xxx"
--spring.datasource.druid.target.password="xxx"
--junx.sharding.migrate.tables=table_a|id,table_b|bid,table_c
注意,数据库线程池采用的druid,启动参数中按照druid的数据源配置调整即可。最简单的配置如上所示,修改对应的参数后,就可以启动junx-shardingsphere-datamigrate了。
配置说明
junx-shardingsphere-datamigrate提供了数据迁移时候的一些基础配置,用于数据迁移时候的抽取和写入流量控制,可根据自己的环境配置进行合理的设置,这些配置都可以在程序的启动脚本中进行调整,这里主要说明一下数据迁移引擎相关配置,其他基础的配置参考springboot相关配置说明,这里不做赘述。
junx:
sharding:
migrate:
clear-primary-key-value: true #写入数据的时候,是否需要清除主键值,默认true
default-primary-key-name: id #默认数据库中表的关键字列名,在抽取数据过后会去掉原表关键字列,采用sharding的分片主键生成机制
extract-batch-size: 2000 #数据抽取每批记录条数
extract-executor: #数据抽取线程池配置,注意一张表有且仅有一个线程来抽取
name-prefix: data-extract- #数据抽取线程前缀
min-spare-threads: 3 #允许的最大空闲线程数
max-threads: 5 #线程池最大线程数,也就是最多允许5张表同时抽取
max-queue-size: 100 #最多允许100张表待抽取
rejected-execution-handler: CallerRuns #当任务队列超限额的时候,采用的处理方式,有Abort中断、Discard放弃执行、CallerRuns调用者线程自己执行、DiscardOldest放弃最长时间没有执行的任务,将新任务加入到队尾
write-batch-size: 2000 #数据写入抽取每批记录条数
wirte-executor: #数据写入线程池配置,同抽取线程池
name-prefix: data-write- #数据写入线程前缀
min-spare-threads: 5
max-threads: 20 #最大允许20个线程同时写
rejected-execution-handler: CallerRuns #背压一下,让call线程自己执行,缓冲一下
max-queue-size: 10 #这个不能设置太大,因为每次事件发extract-batch-size条数据在内存中,太多任务排队,容易内存溢出
tables: #需要抽取的表名|主键
- xxxx|id
- yyyy #如果不配置主键名,则走junx.sharding.migrate.default-primary-key-name设置的主键名
提示: executor相关配置,请参考https://gitee.com/junxworks/junx/blob/master/junx-core/src/main/java/io/github/junxworks/junx/core/executor/ExecutorConfig.java
额外提示: 需要注意的是有3个配置需要关联上一起配置,分别是junx.sharding.migrate.wirte-executor数据写入线程池、junx-shardingsphere-datamigrate应用程序本身的target数据库连接池大小以及即将写入的shardingsphere-proxy配置的后端数据库连接池大小,这几个需要关联起来一起配置,写入线程池配大了,会导致线程队列阻塞等待获取target数据库连接,shardingsphere-proxy配置的数据源小了,会往目标库导致写入数据慢。这个资源池大小配置建议 shardingsphere-proxy后端数据库连接池 > target数据库连接池 > junx.sharding.migrate.wirte-executor数据写入线程池【最终决定资源池大小的是数据库服务器的配置,一切配置都围绕数据库服务器处理能力去设置】。
API接口说明
junx-shardingsphere-datamigrate是一个web应用,在启动程序后会监听端口为22222(可自行调整),junx-shardingsphere-datamigrate在当前版本提供了5个用于控制数据迁移引擎的API接口,分别如下所示:
- 启动引擎:http://localhost:22222/junx-sharding/data-migrate/start
启动引擎后,就开始进行表数据抽取,根据事先设置好的数据抽取执行线程池参数,进行并行抽取。 - 暂停引擎:http://localhost:22222/junx-sharding/data-migrate/suspend
暂停引擎过后,会block住数据抽取线程(数据写入线程依然会正常写入),直到恢复引擎。 - 恢复引擎:http://localhost:22222/junx-sharding/data-migrate/resume
将引擎从暂停状态恢复回来,继续数据抽取操作。 - 停止引擎:http://localhost:22222/junx-sharding/data-migrate/shutdown
将整个数据迁移引擎停止,包括数据抽取和数据写入操作,相当于终止数据迁移。(无法恢复,要再执行只能从头开始) - 重启引擎:http://localhost:22222/junx-sharding/data-migrate/restart
重启引擎,相当于先停止引擎,再启动引擎。
在调用启动引擎接口之后,就可以看到数据迁移引擎打印的日志信息了:

结语
当前1.1.0版本做得相对比较简单,仅仅是配置数据迁移的表,然后启动数据迁移引擎,等待迁移结果就行了。后期如果有机会,还是要做成独立的控制台,有持久化的数据,能灵活配置数据源,能任意启动选中表的同步,能查看当前的任务进度等等。
标题:ShardingSphere基于junx-shardingsphere-datamigrate+shardingsphere-proxy做单/多表数据迁移
作者:michael
地址:https://blog.junxworks.cn/articles/2021/09/24/1632452885363.html