ShardingSphere分库分表改造之sharding-scaling+shardingsphere-proxy全量&增量数据迁移/扩容
Sharding-Scaling简介
Apache ShardingSphere 提供了数据分片的能力,可以将数据分散到不同的数据库节点上,提升整体处理能力。 但对于使用单数据库运行的系统来说,如何安全简单地将数据迁移至水平分片的数据库上,一直以来都是一个迫切的需求; 同时,对于已经使用了 Apache ShardingSphere 的用户来说,随着业务规模的快速变化,也可能需要对现有的分片集群进行弹性扩容或缩容。
- 老项目首次使用Sharding-JDBC按照一定的规则分库分表,老数据怎么办?
- 老项目已经使用了Sharding-JDBC将数据分成了2库2表,现在数据量还是很大,想分成10库10表,老数据怎么办?
这个就是现实中的数据库的弹性伸缩的场景,Sharding-Scaling就是ShardingSphere给出的一个提供给用户的通用数据接入迁移及弹性伸缩的解决方案
弹性伸缩方案架构
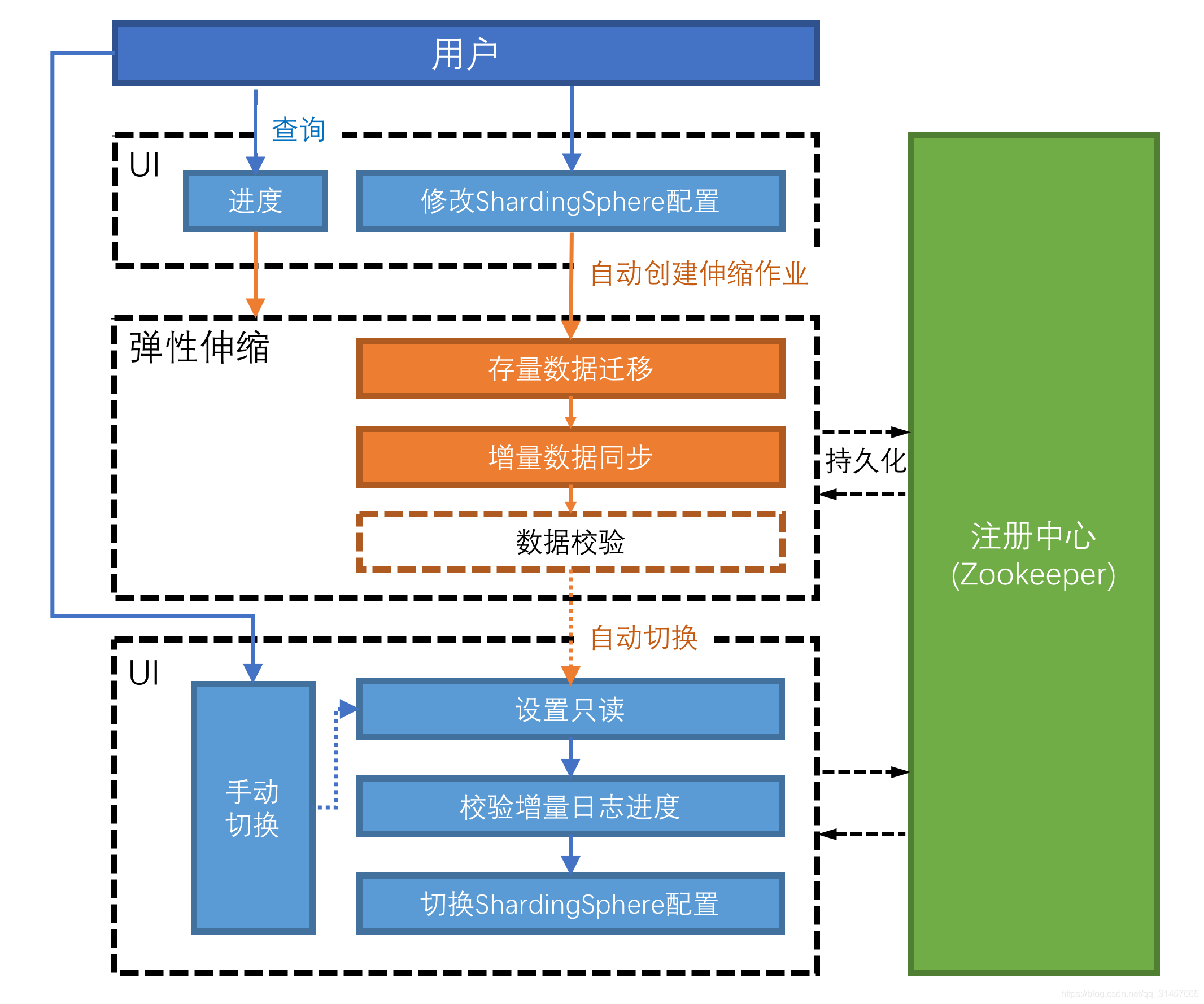
挑战
Apache ShardingSphere 在分片策略和算法上提供给用户极大的自由度,但却给弹性伸缩造成了极大的挑战。 如何找到一种方式,即能支持各类不同用户的分片策略和算法,又能高效地将数据节点进行伸缩,是弹性伸缩面临的第一个挑战;
同时,弹性伸缩过程中,不应该对正在运行的业务造成影响,尽可能减少伸缩时数据不可用的时间窗口,甚至做到用户完全无感知,是弹性伸缩的另一个挑战;
最后,弹性伸缩不应该对现有的数据造成影响,如何保证数据的可用性和正确性,是弹性伸缩的第三个挑战。
目标
支持各类用户自定义的分片策略,减少用户在数据伸缩及迁移时的重复工作及业务影响,提供一站式的通用弹性伸缩解决方案,是 Apache ShardingSphere 弹性伸缩的主要设计目标。
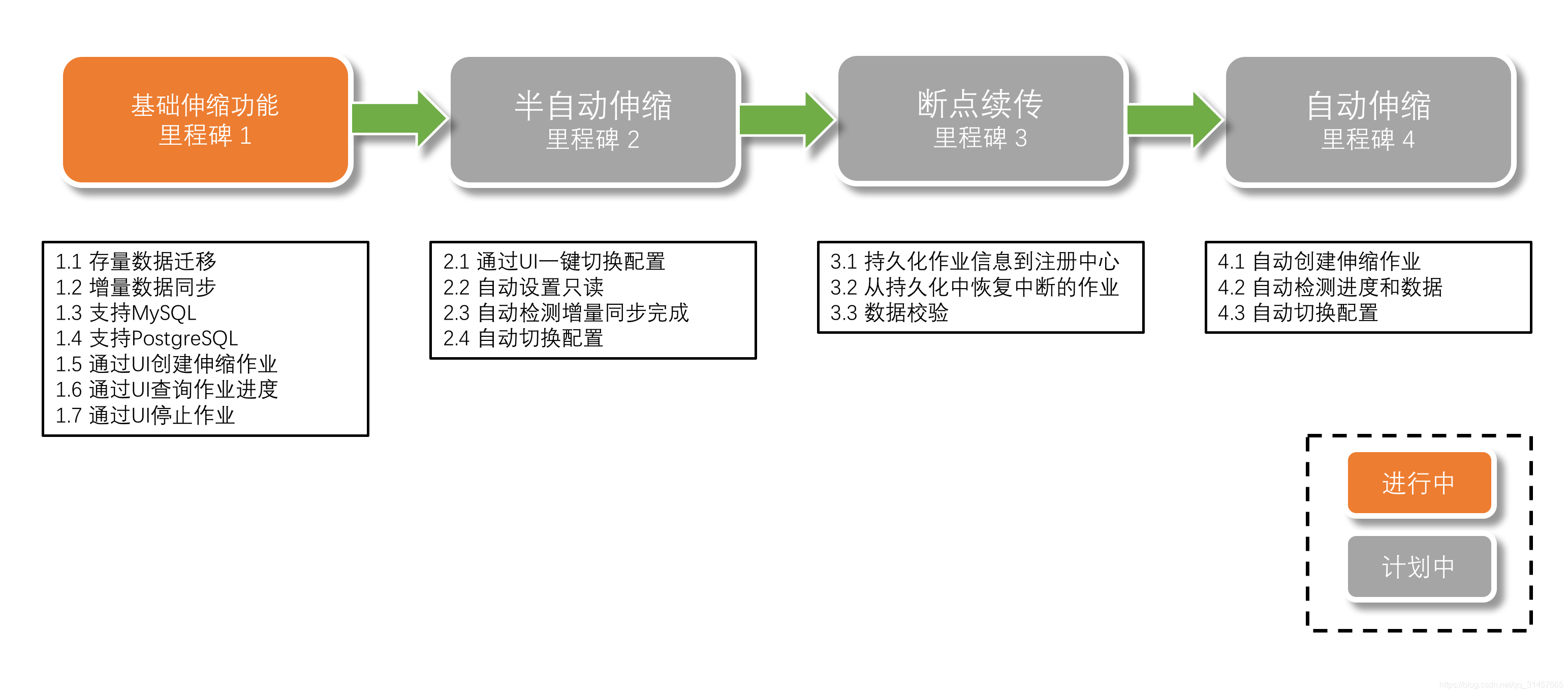
状态
当前处于 alpha 开发阶段。
核心概念
考虑到 Apache ShardingSphere 的弹性伸缩模块的几个挑战,目前的弹性伸缩解决方案为:临时地使用两个数据库集群,伸缩完成后切换的方式实现。
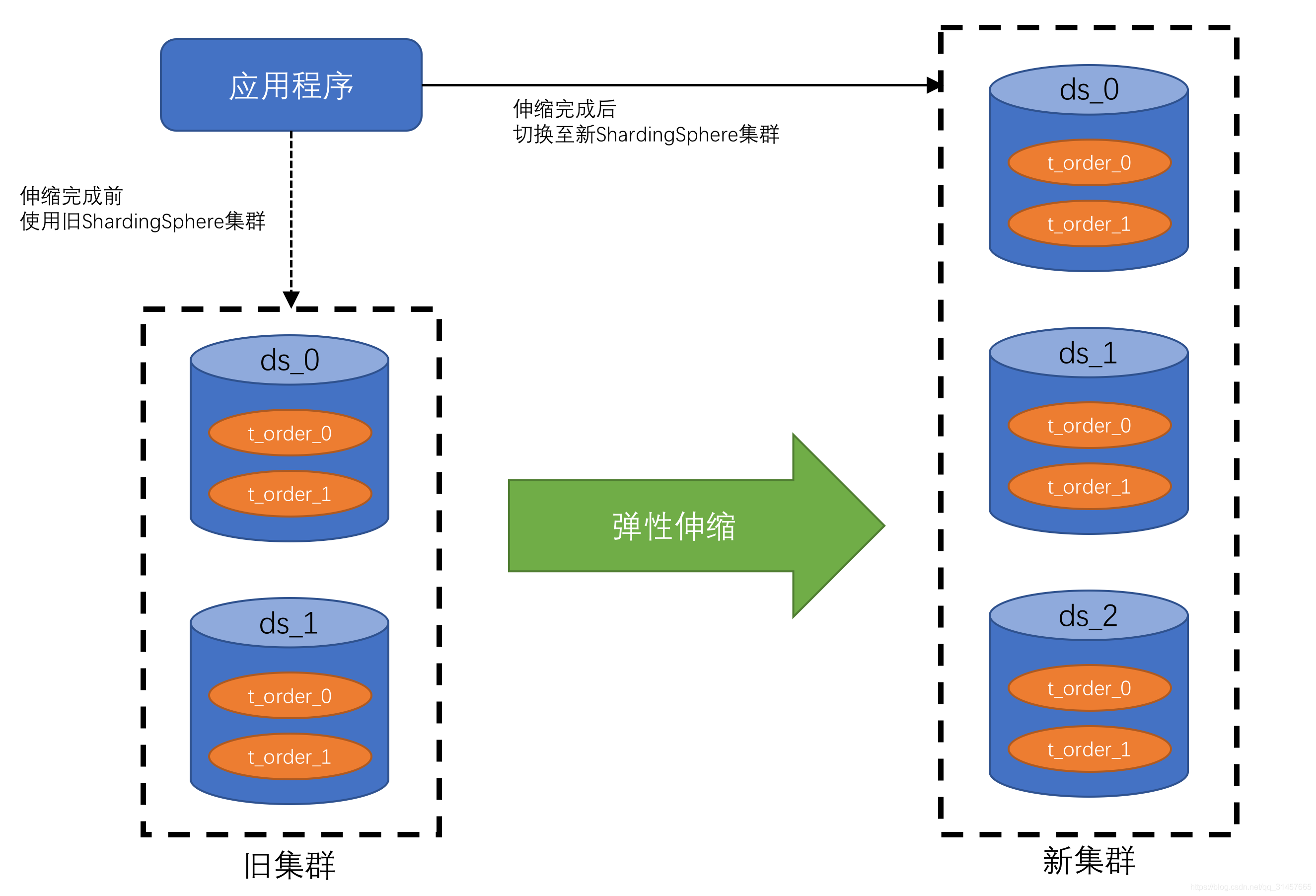
这种实现方式有以下优点:
- 伸缩过程中,原始数据没有任何影响
- 伸缩失败无风险
- 不受分片策略限制
同时也存在一定的缺点:
- 在一定时间内存在冗余服务器
- 所有数据都需要移动
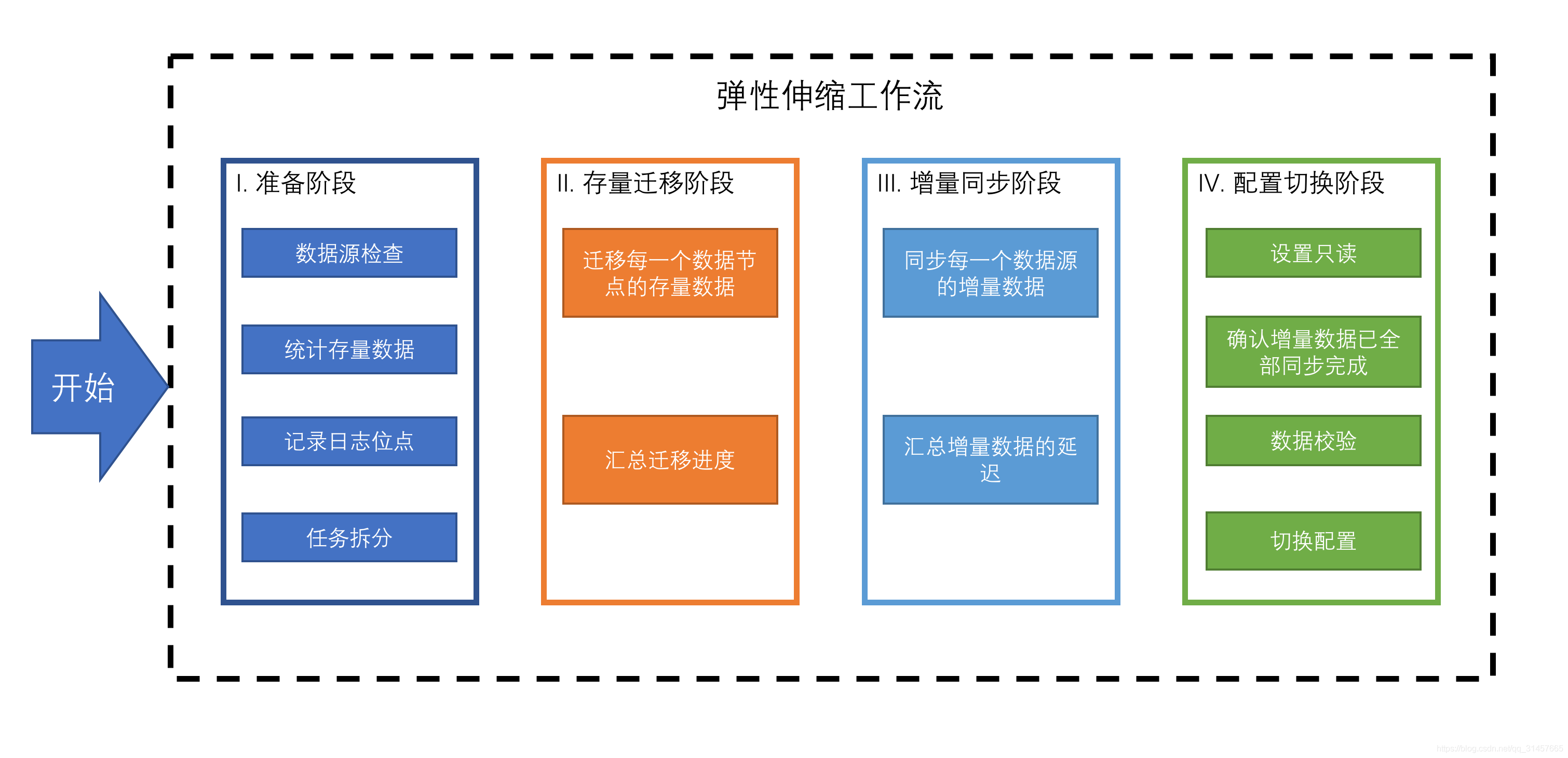
弹性伸缩模块会通过解析旧分片规则,提取配置中的数据源、数据节点等信息,之后创建伸缩作业工作流,将一次弹性伸缩拆解为4个主要阶段
- 准备阶段
- 存量数据迁移阶段
- 增量数据同步阶段
- 规则切换阶段
弹性伸缩测试
环境准备
| 服务 | ip:端口 |
|---|---|
| MySQL | 10.0.0.99:3306 |
| sharding-scaling | 10.0.0.88:8888 |
| sharding-proxy | 10.0.0.88:3307 |
数据迁移规则说明
1、源数据脚本导入
create database `order`;
CREATE TABLE `order`.`t_order` (
`order_id` bigint(20) NOT NULL,
`user_id` int(11) NOT NULL,
`status` varchar(50) DEFAULT NULL,
`order_no` varchar(64) DEFAULT NULL,
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `order`.`t_order` (`order_id`, `user_id`, `status`, `order_no`) VALUES ('1', '2', '1', '1111111');
INSERT INTO `order`.`t_order` (`order_id`, `user_id`, `status`, `order_no`) VALUES ('2', '2', '1', '2222222');
INSERT INTO `order`.`t_order` (`order_id`, `user_id`, `status`, `order_no`) VALUES ('3', '2', '1', '3333333');
INSERT INTO `order`.`t_order` (`order_id`, `user_id`, `status`, `order_no`) VALUES ('4', '3', '1', '4444444');
INSERT INTO `order`.`t_order` (`order_id`, `user_id`, `status`, `order_no`) VALUES ('5', '3', '1', '5555555');
2、扩容库脚本
扩容出2个库,2个分表,对应如下脚本
create database `order_0`;
create database `order_1`;
CREATE TABLE `order_0`.`t_order_0` (
`order_id` bigint(20) NOT NULL,
`user_id` int(11) NOT NULL,
`status` varchar(50) DEFAULT NULL,
`order_no` varchar(64) DEFAULT NULL,
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `order_0`.`t_order_1` (
`order_id` bigint(20) NOT NULL,
`user_id` int(11) NOT NULL,
`status` varchar(50) DEFAULT NULL,
`order_no` varchar(64) DEFAULT NULL,
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `order_1`.`t_order_0` (
`order_id` bigint(20) NOT NULL,
`user_id` int(11) NOT NULL,
`status` varchar(50) DEFAULT NULL,
`order_no` varchar(64) DEFAULT NULL,
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `order_1`.`t_order_1` (
`order_id` bigint(20) NOT NULL,
`user_id` int(11) NOT NULL,
`status` varchar(50) DEFAULT NULL,
`order_no` varchar(64) DEFAULT NULL,
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
3、账号权限创建
sharding-scaling的增量同步基于binlog实现的, 所以账号需要拥有slave权限,RDS可以忽视此步骤, RDS默认创建的账号拥有slave权限
CREATE USER sharding_slave IDENTIFIED BY '123456';
GRANT SELECT,INSERT,UPDATE,DELETE, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'sharding_slave'@'%' ;
FLUSH PRIVILEGES;
4、扩容规则
根据user_id % 2 取模路由到库实例, 根据order_id%2 取模路由到具体表
部署sharding-scaling
需要jdk8环境依赖
该服务的作用是根据指定源数据和目标数据源进行全量同步,且拉取源数据binlog日志进行增量更新
#下载编译包
wget https://linux-soft-ware.oss-cn-shenzhen.aliyuncs.com/sharding-scaling-4.1.0.tar.gz
tar xf sharding-scaling-4.1.0.tar.gz
cd sharding-scaling-4.1.0
#启动服务
./bin/start.sh
#检查是否启动成功
tail -50 logs/stdout.log
部署sharding-proxy
该服务的作用是一个数据库中间件,用户在此服务上编辑好分库分表规则后,sharding-scaling会把源数据写入到sharding-proxy中,由sharding-proxy对数据进行路由写入到对应的库和表
1、下载解压
#下载编译包
wget https://linux-soft-ware.oss-cn-shenzhen.aliyuncs.com/sharding-proxy-4.1.0.tar.gz
tar xf sharding-proxy-4.1.0.tar.gz
cd sharding-proxy-4.1.0
2、编辑账号配置
#在server.yaml最后一行追加以下内容
vim conf/server.yaml
authentication:
users:
root:
password: 123456
3、编辑分库分表配置
#在config-sharding.yaml最后一行追加以下内容
vim conf/config-sharding.yaml
#对外暴露的数据库名称
schemaName: order
dataSources:
ds_0:
url: jdbc:mysql://10.0.0.99:3306/order_0?serverTimezone=UTC&useSSL=false
username: root
password: 123456
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 300
ds_1:
url: jdbc:mysql://10.0.0.99:3306/order_1?serverTimezone=UTC&useSSL=false
username: root
password: 123456
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 300
shardingRule:
tables:
t_order:
actualDataNodes: ds_${0..1}.t_order_$->{0..1}
databaseStrategy:
inline:
shardingColumn: user_id
algorithmExpression: ds_${user_id % 2}
tableStrategy:
inline:
shardingColumn: order_id
algorithmExpression: t_order_${order_id % 2}
keyGenerator:
type: SNOWFLAKE
column: order_id
4、启动
./bin/start.sh
#检查是否启动成功
tail -10 logs/stdout.log
5、校验配置正确性
#使用mysql客户端检查是否能链接成功
mysql -h 10.0.0.88 -p 3307 -uroot -p123456
#检查数据库名称是否正确
mysql> show databases;
+--------------+
| Database |
+--------------+
| order |
+--------------+
#执行以下脚本,写入成功后, 检查order_0 order_1的分表数据是否按照规则落库
mysql> use order;
mysql> INSERT INTO `t_order` (`order_id`, `user_id`, `status`, `order_no`) VALUES (1, 2, '1', '1111111');
mysql> INSERT INTO `t_order` (`order_id`, `user_id`, `status`, `order_no`) VALUES (2, 2, '1', '2222222');
mysql> INSERT INTO `t_order` (`order_id`, `user_id`, `status`, `order_no`) VALUES (3, 2, '1', '3333333');
mysql> INSERT INTO `t_order` (`order_id`, `user_id`, `status`, `order_no`) VALUES (4, 3, '1', '4444444');
mysql> INSERT INTO `t_order` (`order_id`, `user_id`, `status`, `order_no`) VALUES (5, 3, '1', '5555555');
mysql> INSERT INTO `t_order` (`order_id`, `user_id`, `status`, `order_no`) VALUES (6, 3, '1', '6666666');
#检查无误后, 删除测试数据
mysql> delete from t_order
迁移数据
1、新建一个迁移数据任务
重要入参说明:
Sharding-scalingAPI接口
弹性迁移组件提供了简单的HTTP API接口
创建迁移任务
接口描述:POST /shardingscaling/job/start
请求体:

curl -X POST --url http://localhost:8888/shardingscaling/job/start \
--header 'content-type: application/json' \
--data '{
"ruleConfiguration": {
"sourceDatasource": "ds_0: !!org.apache.shardingsphere.orchestration.core.configuration.YamlDataSourceConfiguration\n dataSourceClassName: com.zaxxer.hikari.HikariDataSource\n properties:\n jdbcUrl: jdbc:mysql://10.0.0.99:3306/order?serverTimezone=UTC&useSSL=false&zeroDateTimeBehavior=convertToNull\n driverClassName: com.mysql.jdbc.Driver\n username: sharding_slave\n password: 123456\n connectionTimeout: 30000\n idleTimeout: 60000\n maxLifetime: 1800000\n maxPoolSize: 100\n minPoolSize: 10\n maintenanceIntervalMilliseconds: 30000\n readOnly: false\n",
"sourceRule": "tables:\n t_order:\n actualDataNodes: ds_0.t_order\n keyGenerator:\n column: order_id\n type: SNOWFLAKE",
"destinationDataSources": {
"name": "dt_1",
"password": "123456",
"url": "jdbc:mysql://10.0.0.88:3307/order?serverTimezone=UTC&useSSL=false",
"username": "root"
}
},
"jobConfiguration": {
"concurrency": 1
}
}'
#返回的消息如下就代表成功
{"success":true,"errorCode":0,"errorMsg":null,"model":null}
2、查看任务详情进度
#后面的1,是你提交任务的顺序,从1开始,如果你后面又提交了一个任务,那应该改为2
curl http://localhost:8888/shardingscaling/job/progress/1
#返回的消息内容
#关注2个字段 estimatedRows:计划同步的数量 syncedRows: 已同步数量
#我们可以明显看到已经同步成功了, 你也可以到具体的实例中查看,这里就不查了
{
"success": true,
"errorCode": 0,
"errorMsg": null,
"model": {
"id": 1,
"jobName": "Local Sharding Scaling Job",
"status": "RUNNING",
"syncTaskProgress": [{
"id": "10.0.0.99-3306-order",
"status": "SYNCHRONIZE_REALTIME_DATA",
"historySyncTaskProgress": [{
"id": "history-order-t_order#0",
"estimatedRows": 5,
"syncedRows": 5
}],
"realTimeSyncTaskProgress": {
"id": "realtime-order",
"delayMillisecond": 1549,
"logPosition": {
"filename": "mysql-bin.000040",
"position": 12903,
"serverId": 0
}
}
}]
}
}
3、校验增量数据是否同步到扩容库
3.1、在老库模拟一条增量数据
INSERT INTO `order`.`t_order` (`order_id`, `user_id`, `status`, `order_no`) VALUES ('6', '3', '1', '6666666');
3.2、在sharding-proxy查看增量数据是否进来
[root@mysql ~]# mysql -h 10.0.0.88 -P 3307 -uroot -p123456
mysql> use order;
mysql> select * from t_order;
+----------+---------+--------+----------+
| order_id | user_id | status | order_no |
+----------+---------+--------+----------+
| 2 | 2 | 1 | 2222222 |
| 1 | 2 | 1 | 1111111 |
| 3 | 2 | 1 | 3333333 |
| 4 | 3 | 1 | 4444444 |
| 6 | 3 | 1 | 6666666 |
| 5 | 3 | 1 | 5555555 |
+----------+---------+--------+----------+
6 rows in set (0.02 sec)
增量数据的确进来了, 到此我们完成了不停服,全量&增量数据平滑迁移到扩容库
需要注意的坑
1、取模的字段类型不允许设置 unsigned 无符号类型,否则全量同步会失败
2、全量同步过程中,sharding-proxy如果挂了会导致同步失败,sharding-scaling 不会进行重试,所以重启sharding-proxy前需要检查提交的任务是否同步成功
3、如果迁移的数据表很多,建议部署多个sharding-scaling 实例,提高同步的吞吐量
4、sharding-scaling如果挂了或者重启了, 增量数据不会进来,需要重新提交同步任务
参考:
https://blog.csdn.net/beichen8641/article/details/106924189
https://blog.csdn.net/qq_31457665/article/details/115336660
https://shardingsphere.apache.org/document/4.1.1/cn/manual/sharding-scaling/usage/
标题:ShardingSphere分库分表改造之sharding-scaling+shardingsphere-proxy全量&增量数据迁移/扩容
作者:michael
地址:https://blog.junxworks.cn/articles/2021/09/18/1631945137624.html