kubernetes(v1.21.1)学习之一kubeadm搭建k8sHA集群
很久没有看k8s相关的东西了,记得在2016年k8s刚问世的时候,当时领导就让我们学习k8s,说这个以后会统治整个容器化部署领域,当时不以为然,觉得有docker就够了,要啥k8s,然而5年过去了,现在k8s俨然已经成为霸主,并且准备把docker一脚踢开,确实k8s的强大大家有目共睹,时隔3年,我又捡起了k8s,当初k8s版本是1.2.4,现在已经到1.21.1了,发展很快,自己搞了半天,连部署这块都不会了,网上搜罗了很多资料,官网也看过,把一些东西总结下来,以便以后回顾。
Kubeadm工具搭建k8s集群
Kubeadm工具的出发点很简单,就是尽可能简单的部署一个生产可用的Kubernetes集群。实际只需要两条命令即可:
# 创建一个 Master 节点
$ kubeadm init
# 将一个 Node 节点加入到当前集群中
$ kubeadm join <Master 节点的 IP 和端口 >
kubeadm做了这些事
执行 kubeadm init时:
- 自动化的集群机器合规检查
- 自动化生成集群运行所需的各类证书及各类配置,并将Master节点信息保存在名为cluster-info的ConfigMap中。
- 通过static Pod方式,运行API server, controller manager 、scheduler及etcd组件。
- 生成Token以便其他节点加入集群
执行 kubeadm join时:
- 节点通过token访问kube-apiserver,获取cluster-info中信息,主要是apiserver的授权信息(节点信任集群)。
- 通过授权信息,kubelet可执行TLS bootstrapping,与apiserver真正建立互信任关系(集群信任节点)。
简单来说,kubeadm做的事就是把大部分组件都容器化,通过StaticPod方式运行,并自动化了大部分的集群配置及认证等工作,简单几步即可搭建一个可用Kubernetes的集群。
这里有个问题,为什么不把kubelet组件也容器化呢,是因为kubelet在配置容器网络、管理容器数据卷时,都需要直接操作宿主机,而如果现在 kubelet 本身就运行在一个容器里,那么直接操作宿主机就会变得很麻烦。比如,容器内要做NFS的挂载,需要kubelet先在宿主机执行mount挂载NFS。如果kubelet运行在容器中问题来了,如果kubectl运行在容器中,要操作宿主机的Mount Namespace是非常复杂的。所以,kubeadm选择把kubelet运行直接运行在宿主机中,使用容器部署其他Kubernetes组件。所以,Kubeadm部署要安装的组件有Kubeadm、kubelet、kubectl三个。
上面说的是kubeadm部署方式的一般步骤,kubeadm部署是可以自由定制的,包括要容器化哪些组件,所用的镜像,是否用外部etcd,是否使用用户证书认证等以及集群的配置等等,都是可以灵活定制的,这也是kubeadm能够快速部署一个高可用的集群的基础。详细的说明可以参考官方Reference。但是,kubeadm最重要的作用还是解决集群部署问题,而不是集群配置管理的问题,官方也建议把Kubeadm作为一个基础工具,在其上层再去量身定制适合自己的集群的管理工具(例如minikube)。
通过kubeadm初始化控制平面节点
控制平面节点是运行控制平面组件的机器, 包括 etcd (集群数据库) 和 API Server (命令行工具 kubectl 与之通信)。
- (推荐)如果计划将单个控制平面 kubeadm 集群升级成高可用, 你应该指定
--control-plane-endpoint为所有控制平面节点设置共享端点。 端点可以是负载均衡器的 DNS 名称或 IP 地址。 - 选择一个Pod网络插件,并验证是否需要为
kubeadm init传递参数。 根据你选择的第三方网络插件,你可能需要设置--pod-network-cidr的值。 请参阅 安装Pod网络附加组件。 - (可选)从版本1.14开始,
kubeadm尝试使用一系列众所周知的域套接字路径来检测 Linux 上的容器运行时。 要使用不同的容器运行时, 或者如果在预配置的节点上安装了多个容器,请为kubeadm init指定--cri-socket参数。 请参阅安装运行时。 - (可选)除非另有说明,否则
kubeadm使用与默认网关关联的网络接口来设置此控制平面节点 API server 的广播地址。 要使用其他网络接口,请为kubeadm init设置--apiserver-advertise-address=参数。 要部署使用 IPv6 地址的 Kubernetes 集群, 必须指定一个 IPv6 地址,例如--apiserver-advertise-address=fd00::101 - (可选)在
kubeadm init之前运行kubeadm config images pull,以验证与 gcr.io 容器镜像仓库的连通性。
Kubernetes控制平面节点的高可用
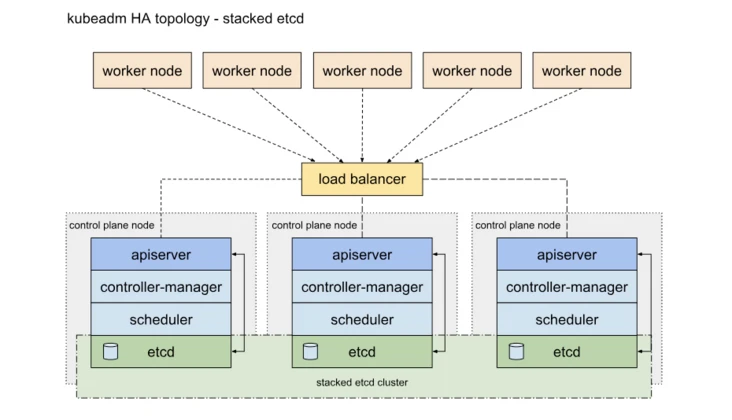
Kubernetes的高可用主要指的是控制平面的高可用,简单说,就是有多套Master节点组件和etcd组件,工作节点通过负载均衡连接到各Master。HA有两种做法,一种是将etcd与Master节点组件混布在一起:
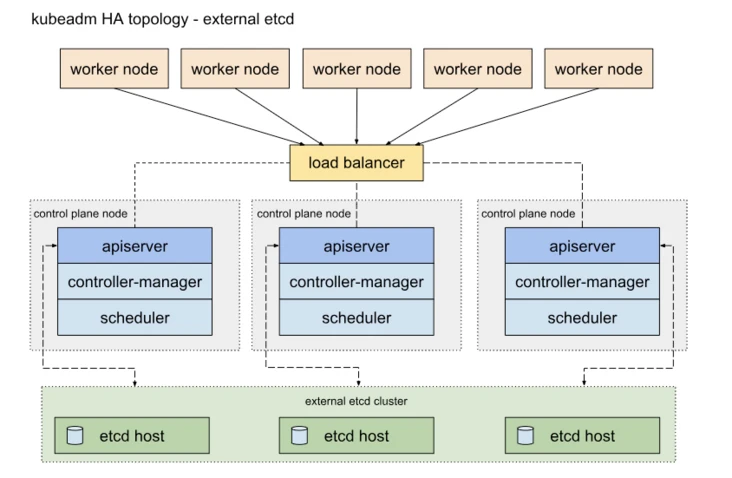
另外一种方式是,使用独立的Etcd集群,不与Master节点混布:
两种方式的相同之处在于都提供了控制平面的冗余,实现了集群高可以用,区别在于:
Etcd混布方式:
- 所需机器资源少
- 部署简单,利于管理
- 容易进行横向扩展
- 风险大,一台宿主机挂了,master和etcd就都少了一套,集群冗余度受到的影响比较大。
Etcd独立部署方式:
- 所需机器资源多(按照Etcd集群的奇数原则,这种拓扑的集群关控制平面最少就要6台宿主机了)。
- 部署相对复杂,要独立管理etcd集群和和master集群。
- 解耦了控制平面和Etcd,集群风险小健壮性强,单独挂了一台master或etcd对集群的影响很小。
部署环境
在本地采用VMware虚拟机来搭建整个k8s集群,由于机器配置有限,准备了4个虚拟服务器:
master:192.168.1.222 4c4G centos8_stream Linux version 4.18.0-301.1.el8.x86_64
slave1:192.168.1.223 2c4G centos8_stream Linux version 4.18.0-301.1.el8.x86_64
slave2:192.168.1.224 2c4G centos8_stream Linux version 4.18.0-301.1.el8.x86_64
registry:192.168.1.225 2c2G centos8_stream Linux version 4.18.0-301.1.el8.x86_64
haproxy:192.168.1.225 (与registry共用一台虚拟机)
- 集群版本
kubeadm:1.21.1
Kubernetes:1.21.1
Docker:Community 20.10.7
haproxy: 1.8.27-493ce0b
准备工作
在所有节点上操作:
- 关闭selinux,firewall
setenforce 0
sed -i 's/SELINUX=enforcing/SELINUX=permissive/' /etc/selinux/config
systemctl stop firewalld
systemctl disable firewalld
- 关闭swap,(1.8版本后的要求,目的应该是不想让swap干扰pod可使用的内存limit)
swapoff -a
#永久关闭swap
sed -ri 's/.*swap.*/#&/' /etc/fstab
- 修改下面内核参数,否则请求数据经过iptables的路由可能有问题
cat <<EOF > /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl --system
- 安装k8组件、docker
在除了haproxy以外所有节点上操作
将Kubernetes安装源改为阿里云,方便国内网络环境安装
cat << EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
- 安装docker-ce
wget -O /etc/yum.repos.d/docker-ce.repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
yum install -y docker-ce
- 安装kubelet kubeadm kubectl
yum install -y kubelet kubeadm kubectl
安装配置负载均衡
在haproxy节点操作:
# 安装haproxy
yum install haproxy -y
# 修改haproxy配置
cat << EOF > /etc/haproxy/haproxy.cfg
global
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
defaults
mode tcp
log global
retries 3
timeout connect 10s
timeout client 1m
timeout server 1m
frontend kube-apiserver
bind *:6443 # 指定前端端口
mode tcp
default_backend master
backend master # 指定后端机器及端口,负载方式为轮询
balance roundrobin
server master-1 192.168.1.222:6443 check maxconn 2000
EOF
# 开机默认启动haproxy,开启服务
systemctl enable haproxy
systemctl start haproxy
# 检查服务端口情况:
[root@server-master ~]# netstat -ntlp | grep 6443
tcp6 0 0 :::6443 :::* LISTEN 21080/kube-apiserve
部署Kubernetes
在master节点操作:
- 准备集群配置文件,目前用的api版本为v1beta2,具体配置可以参考官方reference
cat << EOF > /root/kubeadm-config.yaml
apiVersion: kubeadm.k8s.io/v1beta2
kind: ClusterConfiguration
kubernetesVersion: v1.21.1 # 指定1.21.1版本
controlPlaneEndpoint: 192.168.1.225:6443 # haproxy地址及端口
imageRepository: registry.cn-hangzhou.aliyuncs.com/google_containers # 指定镜像源为阿里源
networking:
podSubnet: 10.32.0.0/12 # 计划使用kube-router网络插件,指定pod网段及掩码
EOF
- 执行节点初始化
systemctl enable kubelet
systemctl start kubelet
kubeadm config images pull --config kubeadm-config.yaml # 通过阿里源预先拉镜像
kubeadm init --config=kubeadm-config.yaml --upload-certs
【异常处理】注意:k8s1.21.1版本有个组件是coredns/coredns:v1.8.0,这个组件在阿里云的镜像仓库里面是coredns:1.8.0,导致kubeadm下载镜像的时候一直异常,这里我们可以通过自己搭建docker镜像仓库的方式来解决这个问题,把所有k8s需要的镜像都push到私有仓库中
在registry服务器(192.168.1.225)上执行下面命令
#搭建docker私有仓库
docker pull registry
mkdir /usr/lib/registry
docker run -d -p 5000:5000 --restart=always --name registry -v /usr/lib/registry:/var/lib/registry registry:latest
#registry默认是https访问的,如果需要http方式访问,请在需要访问私有仓库的服务器上修改docker启动参数
vim /usr/lib/systemd/system/docker.service
在ExecStart参数后面添加--insecure-registry 192.168.1.225:5000,修改好后重启docker服务
在/etc/docker/daemon.json文件中新增(没有这个文件就新建)
{
"exec-opts": ["native.cgroupdriver=systemd"]
}
systemctl daemon-reload
systemctl restart docker
私有仓库搭建好后,可以通过如下命令拉取coredns镜像:
docker pull coredns/coredns:1.8.0
docker tag coredns/coredns:1.8.0 192.168.1.225:5000/coredns/coredns:v1.8.0
docker push 192.168.1.225:5000/coredns/coredns:v1.8.0
将所有必须镜像push到私有仓库后,即可执行
kubeadm init --config=kubeadm-config.yaml --upload-certs
【异常处理】我这里执行的时候又出现异常,如下所示:
[root@server-master ~]# kubeadm init --config=kubeadm-config.yaml --upload-certs
[init] Using Kubernetes version: v1.21.1
[preflight] Running pre-flight checks
[WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/
[WARNING Hostname]: hostname "server-master" could not be reached
[WARNING Hostname]: hostname "server-master": lookup server-master on 114.114.114.114:53: no such host
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR Port-6443]: Port 6443 is in use
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher
#遇到这个情况时,需要做以下两步:
1、在/etc/docker/daemon.json文件中新增(没有这个文件就新建)
{
"exec-opts": ["native.cgroupdriver=systemd"]
}
重启docker
systemctl daemon-reload
systemctl restart docker
2、将server-master加入到/etc/hosts中
192.168.1.222 server-master
再次执行 kubeadm init --config=kubeadm-config.yaml --upload-certs,执行成功后,可以看到如下结果:
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of the control-plane node running the following command on each as root:
kubeadm join 192.168.1.225:6443 --token gijcgb.r3dmax8587cold50 \
--discovery-token-ca-cert-hash sha256:5a883d73c1fb0d967485512e4018c32979abe39838fe265b9c0cd7669ced0a20 \
--control-plane --certificate-key 91d350404371652f566a3d08794493b8131c9a36c6d9136b5150bdcadd40517d
Please note that the certificate-key gives access to cluster sensitive data, keep it secret!
As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use
"kubeadm init phase upload-certs --upload-certs" to reload certs afterward.
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.1.225:6443 --token gijcgb.r3dmax8587cold50 \
--discovery-token-ca-cert-hash sha256:5a883d73c1fb0d967485512e4018c32979abe39838fe265b9c0cd7669ced0a20
到这里,master节点就部署完成。在master 节点,执行kubectl get no,可以看到,集群中已经有1台master节点了
[root@server-master ~]# kubectl get no
NAME STATUS ROLES AGE VERSION
server-master NotReady control-plane,master 9m46s v1.21.1
【异常处理】如果在master节点执行kubectl命令报如下的错误:
The connection to the server localhost:8080 was refused - did you specify the right host or port?
这时候需要调整系统变量:
vim /etc/profile 在底部增加新的环境变量 export KUBECONFIG=/etc/kubernetes/admin.conf
source /etc/profile
初始化网络组件
执行完master初始化过后,k8s的api服务就会启动,但是现在cordns服务还在pending,因为需要网络组件,我们采用kube-router作为网络组件,采用如下步骤进行安装:
KUBECONFIG=/etc/kubernetes/admin.conf kubectl apply -f https://raw.githubusercontent.com/cloudnativelabs/kube-router/master/daemonset/kubeadm-kuberouter-all-features.yaml
【异常处理】如果在kube-router启动的时候,遇到/run/xtables.lock不是文件的问题,请执行下面命令
rm -rf /run/xtables.lock
touch /run/xtables.lock
正常情况下,步骤执行完成后,会有如下结果:
[root@server-master kube-router]# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-6dbf846856-qbh4q 1/1 Running 0 15m
coredns-6dbf846856-qghzb 1/1 Running 0 15m
etcd-server-master 1/1 Running 0 16m
kube-apiserver-server-master 1/1 Running 0 16m
kube-controller-manager-server-master 1/1 Running 0 16m
kube-proxy-tt58p 1/1 Running 0 15m
kube-router-r2zb6 1/1 Running 1 9m48s
kube-scheduler-server-master 1/1 Running 0 16m
继续,需要卸载之前安装的kube-proxy组件,因为我们安装的是全功能的kube-router有service proxy、 firewall 和 pod networking。
KUBECONFIG=/etc/kubernetes/admin.conf kubectl -n kube-system delete ds kube-proxy
docker run --privileged -v /lib/modules:/lib/modules --net=host 192.168.1.225:5000/kube-proxy:v1.21.1 kube-proxy --cleanup
执行完成后,可以看到如下内容
[root@server-master kube-router]# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-6dbf846856-qbh4q 1/1 Running 0 26m
coredns-6dbf846856-qghzb 1/1 Running 0 26m
etcd-server-master 1/1 Running 0 27m
kube-apiserver-server-master 1/1 Running 0 27m
kube-controller-manager-server-master 1/1 Running 0 27m
kube-router-r2zb6 1/1 Running 1 20m
kube-scheduler-server-master 1/1 Running 0 27m
master节点做HA
原来的kubeadm版本,join命令只用于工作节点的加入,而新版本加入了 --experimental-contaol-plane 参数后,控制平面(master)节点也可以通过kubeadm join命令加入集群了。
- 加入另外一个master节点(如果有多个master节点的话)
在master-2操作:
kubeadm join 192.168.1.225:6443 --token gijcgb.r3dmax8587cold50 \
--discovery-token-ca-cert-hash sha256:5a883d73c1fb0d967485512e4018c32979abe39838fe265b9c0cd7669ced0a20 \
--experimental-control-plane --certificate-key 91d350404371652f566a3d08794493b8131c9a36c6d9136b5150bdcadd40517d
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
chown $(id -u):$(id -g) $HOME/.kube/config
工作节点加入集群
- 分别在两个slave节点操作:
由于没有DNS服务器,依然需要将192.168.1.223 server-slave1写入到slave1的/etc/hosts中,然后执行如下命令(注意token和cert hash都是master节点生成的):
systemctl enable kubelet.service
systemctl start kubelet.service
systemctl enable docker.service
systemctl start docker.service
kubeadm join 192.168.1.225:6443 --token gijcgb.r3dmax8587cold50 \
--discovery-token-ca-cert-hash sha256:5a883d73c1fb0d967485512e4018c32979abe39838fe265b9c0cd7669ced0a20
#如果遇到cgroup这个问题,请参考master节点的处理方式
在 master节点执行kubectl get no
[root@server-master ~]# kubectl get no
NAME STATUS ROLES AGE VERSION
server-master Ready control-plane,master 37m v1.21.1
server-slave1 Ready <none> 58s v1.21.1
server-slave2 Ready <none> 44s v1.21.1
至此,一个1主节点(支持HA)+2工作节点+私有仓库的k8s集群已经搭建完毕。如果要加入更多的master或node节点,只要多次执行kubeadm join命令加入集群就好,不需要额外配置,非常方便。
标题:kubernetes(v1.21.1)学习之一kubeadm搭建k8sHA集群
作者:michael
地址:https://blog.junxworks.cn/articles/2021/06/10/1623307900007.html