数据中台学习之数据建模
又有一段时间没有写总结了,学而时习之不亦乐乎,学习数据中台有一段时间了,并且在真正的数据中台上面实操了一段时间,对部分概念有所熟悉和理解,下面就整个数据建模的过程,做一个大致的回顾和总结,刚接触数据建模不久,只是记录自己的愚见,如果出现不对的地方,直接留言指正。下面是对整个数据建模的流程画的一个流程图,便于学习和理解,原图链接地址:https://www.processon.com/view/link/6017dc5f5653bb3aa0af6550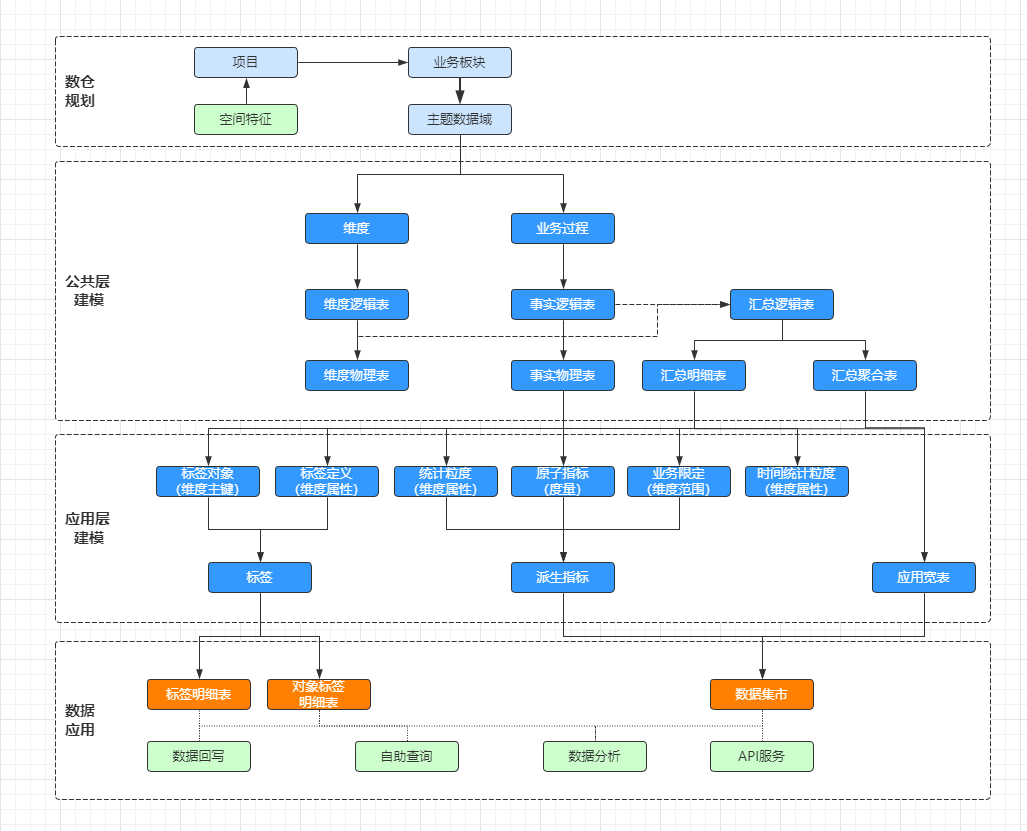
整个数据建模和使用大致分为四个部分,数仓规划、公共层建模、应用层建模、数据应用层,下面就我对这四层的理解做一个大致的介绍。
一、数仓规划
数仓规划层,主要工作还是划分数据领域,我目前是按照业务领域来进行划分的,这块工作对于研发人员来说,不能单干,必须要把产品或者需求分析师拉上一起,把业务领域划分出来,这块非常重要,是整个数据中台的基础,而且不能站在某一个业务系统的角度来看,例如我们目前有核心业务系统、有资金对接系统、有风控系统、额度管理系统等等,在划分数据领域的时候,必须把整个系统架构拉通了看,因为数据中台是全公司全系统共享的,而且这块与后面分业务流程采集数据挂钩,所以数据域划分这块尤为重要。
1、数据域划分
目前我们业务核心数据域划分为:客户域、订单域、产品域、交易域、资金域、经纪人域、支撑域等七个域。每个域代表自己的业务领域,及其产生的数据,这块很重要,每个业务域自己产生的数据由自己模块采集和维护。至于如何划分数据域,仁者见仁智者见智,我个人偏向按业务域来进行划分,这样业务边界更清楚一点。
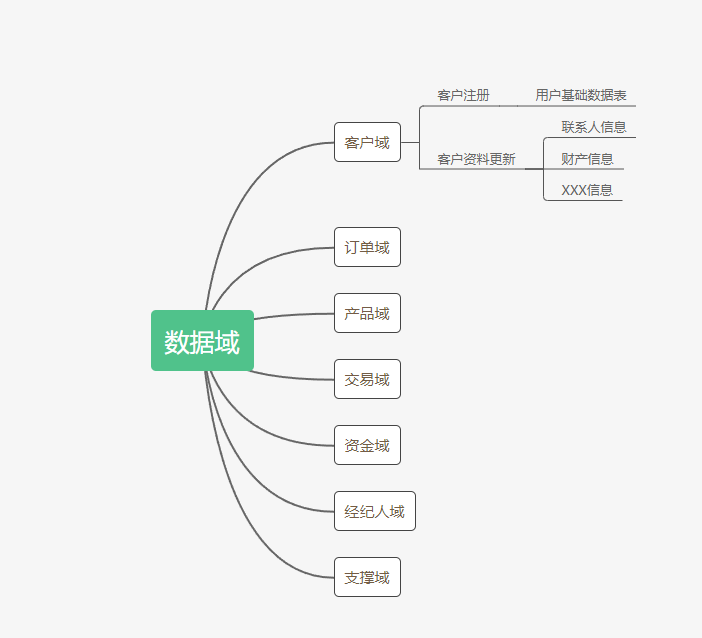
2、业务流程定义
业务流程定义与数据域一样关键,业务流程是每个业务域下面的最小业务单元,我理解的是这些业务单元是产生基础数据的源头,这样按业务单元来进行ODS数据抽取,更容易理解,后期维护更方便。拿客户域举例:
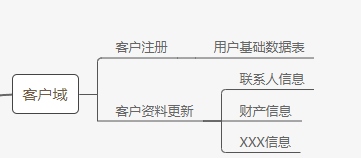
客户域下面有客户注册和客户资料更新,客户注册的时候会写入用户基础数据,客户资料更新的时候会往更多的数据表中写入数据,后期客户资料更新的逻辑有变化,例如新增了工作经历信息,那么很快就能在数据中台中找到对应的业务流程,并修改数据抽取逻辑。
3、ODS贴源表数据抽取
ODS贴源表是数据抽取过来过后数据落地到中台的表,在数据库中的前缀是ods_,数据抽取我觉得是一个比较有争议的地方,到底要不要进行数据清洗?一部分人说不用进行数据清洗,ODS表就是要原滋原味,这样后续出了问题方便追踪。另外一部分人觉得这块要清洗数据,过滤掉没有用的数据,方便后续进行各种业务操作。仁者见仁智者见智,我们目前大部分ODS表是源表数据和表结构,最多加一个同步时间字段,没有进行数据清洗,不过有部分确实比较特殊,部分业务知道有部分数据同步过来过后没法直接用,需要加工一遍,这时候就会涉及到数据清洗,把不要的去掉,有用的数据还得根据其他条件来进行调整。因此数据抽取这块,我们的策略是能保持与源表一致的,就一致,实在有特殊需求的,可以进行清洗。
4、ODS表同步
关于DOS表是否需要同步到查询库,我的答案是肯定的,应该同步,虽然会照成数据冗余,但是会省去很多麻烦,ODS表除了表名,其他基本跟源表一致因此业务系统里面的sql稍微调整一下,基本是可以直接拿到查询库里面执行的,这样排查问题的时候要方便很多。如果ODS表没有同步到查询库,当数据出了问题的时候,需要到计算引擎里面去排查(我们用的是阿里云的MaxCompute),效率会低很多。
二、数据建模
目前我们数据中台是基于One Model方法论进行数据建模的,用的建模方法是维度建模,个人觉得数据建模这块是属于比较难和繁琐的一块,难就难在如何去定义你的数据模型,字段的取舍,宽表的建立。繁琐就是我们目前数据中台的数据模型,每一次调整都会非常的痛苦,例如某个业务表漏了一个字段或者新增了一个字段,要从数据采集ODS表开始,一步一步修改测试发布,直到宽表、派生指标表跑完数据,整个过程都要一遍又一遍的跑。
1、创建事实表
事实表全称是事实数据表,表名前缀是dwd_,事实表是在某个数据域下的,它包含了描述业务域内特定事件的数据,例如订单表包含用户下订单的订单数据。事实表是发生在现实世界中的操作型事件所产生的可度量数据,通常包含大量的行,日常查询请求的主要目标就是基于事实表展开计算和聚合操作。事实表如何创建?首先要定义业务过程,业务过程是业务活动中不可拆分的事件,例如下单、支付和退款。创建业务过程,即从顶层视角,规范业务活动中事件的内容类型及唯一性。在创建业务过程之前,我们需要先将业务中的所涉及到的流程找出来,上面介绍业务过程中不可拆分的事件,而在业务中,我们可以将人与物之间的关系作为过程,比如说开发商与买房者之间的关系有交易,则我们可讲交易作为一个业务过程,然后再梳理出该业务过程的字段有哪些,比如交易有:交易时间、交易额、付款时间等,当我们将业务过程及其字段确定后则可创建业务过程。在定义事实表的同时,我们要考虑到维度表的建立,事实表中需要保留维表的主键,因此不是什么字段都放事实表中存储,当然这块有取舍,也不是事实表里面只放维表的主键,那样的话,事实表就会变成蜈蚣表。事实表里面保留什么字段,个人觉得还得看业务吧,我们目前保留的字段都是后面业务需要的数据,如果业务拓展了,再往事实表中加字段即可,不用一次性建太多字段。
根据维度建模理论,事实表被分成了三种类型,分别是事务事实表、周期快照事实表和累计快照事实表。
事务事实表:事务事实表描述业务过程事务层面的事实,每条记录代表一个事务事件,保留事务事件活动的原始内容。事务事实表中的数据在事务事件发生后进行记录,一般记录数据后就不再更改,其更新方式为增量更新。事务事实表相对其他事实表来说,其保存的数据粒度更细,可以通过事务事实表对事务进行详细的分析。
周期快照事实表:周期快照事实表以具有规律性、可预见的时间间隔产生快照来记录事实,每行代表某个时间周期的一条记录,记录的事实是时间周期内的聚集事实值或状态度量。周期快照表的内容一般在所表达的时间周期结束后才会产生,一般记录后数据就不再更改,其更新方式为增量更新。周期快照事实表一般是简历在事务事实表之上的聚集,维度比事务事实表要少,粒度比事务事实表要粗,但是由于对事务进行了多种形式的加工从而产生了新的事实,故其事实会比事务事实表多。
累计快照事实表:累计快照事实表覆盖一个事务从开始到结束之间所有的关键事件,覆盖事务的整个生命周期,通常具有多个日期字段来记录关键事件的时间点。周期快照事实表涉及的多个事件中任意一个的产生都要做记录,由于周期快照事实表涉及的多个事件的首次加载和后续更新时间是不确定的,因此在首次加载后允许对记录进行更新,一般采用全量刷新的方式更新。累计快照事实表一般用于追踪某个业务的全生命周期及状态转换,比如交易业务,涉及下单、支付、发货、确认收货,这些相关事件在不同的事务事实表中,通过事务事实表很难看到不同事件之间的转化及状态变化,通过累计快照事实表可把相关事件串起来放在一条记录中,这样就很容易解决了。
2、创建维表
什么是维表呢?维表英文全称Dimension Table,维度表,维表在数据库里面的前缀是dim_,维度即进行数据统计的对象。通常情况下,维度是实际存在、不因事件发生而存在的实体,例如时间维度、地区维度、产品维度等。创建维度,即从顶层规范业务中实体(或称主数据)的存在性及唯一性。在创建维度之前,我们需要先将业务中的维度找出来,上面介绍维度是进行数据统计的对象,而在业务中,我们可以将人和物都归为维度,所以我们可以将业务中出现的人和物找出来,比如房地产行业售房业务中,我们可以找到开发商、买房者、中介、房子等这些,则我们可以将这些作为维度,然后再罗列出对应的属性,比如买房者这一维度所带的属性有姓名、年龄、性别、身份证号、有无房贷等,当我们将维度对象及对象属性确定后则可以创建维度了。我觉得正常情况下,维表不会单独使用,而是结合事实表一起使用,维表作为事实表的属性扩展而存在。当然维表也会定义一些标准,例如用户维表,所有关联用户维表的数据,都会有该维表的属性。
3、创建宽表
什么是宽表呢?查阅了很多资料,没有一个权威的定义,首先宽表肯定不是因为数据字段多才叫宽表的,不过很多人认同的就是宽表是由事实表+维表+指标表汇总而成的表,在我们数据库,宽表的前缀是dws_,如果对于宽表有不同的理解的可以留言指正。我们中台的话,宽表主要是由其他宽表、事实表和维表组成,之前也翻阅了很资料,我们数据中台的宽表建模的话,主要还是基于雪花与星座模型在创建,目前主要的维度建模方法有三种,星型、雪花和星座模型,三种类型各有优缺点吧,目前对这块接触不深,领悟不够,多半是查询网上的资料,找到自己想要的那种类型,个人觉得雪花和星座模型比较好,通用性和扩展性更强,能适应不同的业务场景。这里的建模,有点类型Java程序开发里面的模块化思想,将数据分割成口径统一、业务内聚并且相对独立的模块,如果要使用的话,按照某种约定条件(主键关联)的方式,将多个数据模块组装在一起即可,某个模块有了变更,不会影响到其他业务模块,而且修改逻辑过后对所有使用的宽表都会生效,个人觉得这种方式是很好的,体现了一种开闭原则(写过代码的人对这个原则会比较熟悉)。下面对三种建模方式进行简单的说明:
星型模型:它由事实表(FactTable)和维表(DimensionTable)组成。事实表中的维度外键分别与相对应的维表中的主键相关联,关联之后由于形状看起来像是一个星星,所以形象的称为星型模型。
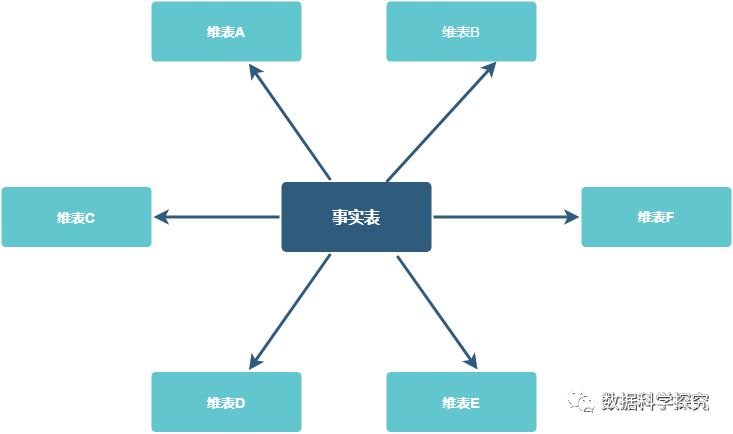
雪花模型:当有一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上时,其图解就像一个雪花,故称雪花模型。
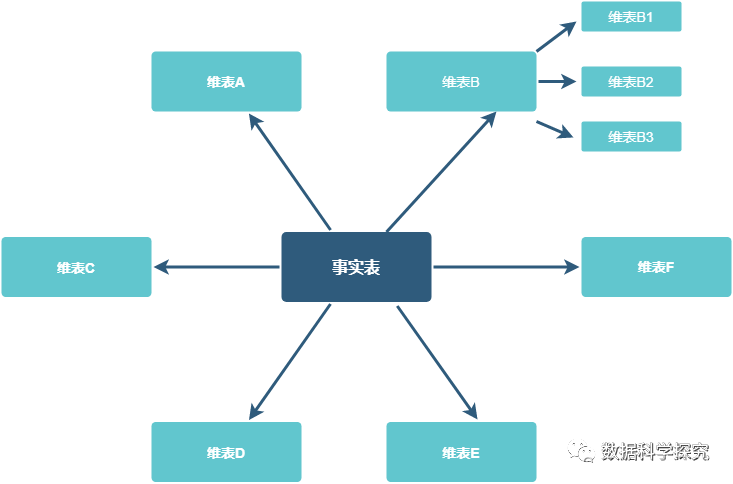
星座模型:星座模型也是星型模式的扩展。基于这种思想就有了星座模式。星型和雪花模型都是多维表对应单事实表,但在很多时候维度空间内的事实表不止一个,而一个维表也可能被多个事实表用到。在业务发展后期,绝大部分维度建模都采用的是星座模式。
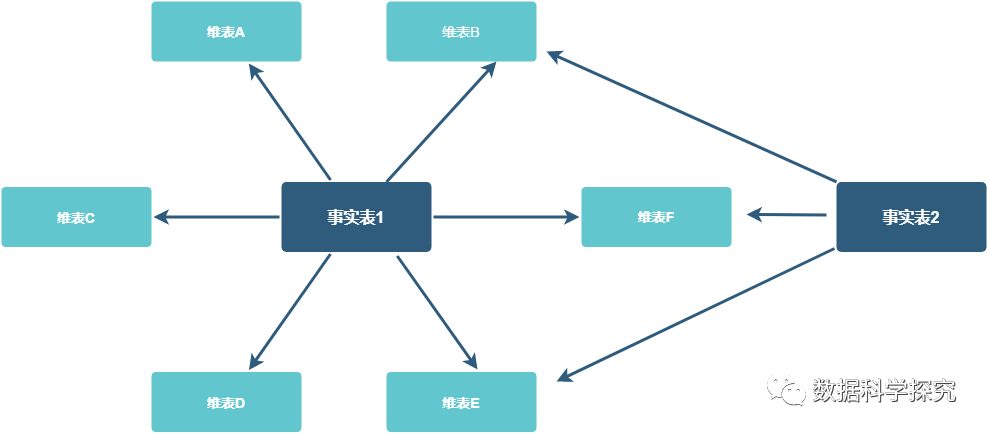
4、创建派生指标表
在数据中台中,派生指标表的前缀是ads_,指标表,顾名思义,相关的统计指标,记录了业务运转过程中产生的度量事实。这里抽象成一个个指标表,主要还是从统计的口径一致性考虑,这里的一致性,指在企业内外部对指标的命名、业务理解、计算方法、统计口径保持一致,避免不同部门对同一个指标的数据理解不一致。这里的派生指标=原子指标+时间修饰词+其他修饰类型:

建议每个原子指标一个指标表,这样使用会更灵活,数据冗余就冗余吧,反正数据中台不是按第三范式来建的。
三、结语
标签层在大数据应用里面来说非常关键,是大数据的核心价值和魅力的体现,由于现在业务简单,暂时还没有用到标签数据层,这里深表遗憾,以后有机会还是要研究一下这一层的意义和逻辑。现在对整个数据中台建模有了一定的了解,刚接触不久,学习之余总结一下,对自己以后的回顾也好,学习也好都有帮助,同时也能分享一下自己的观点和看法,何乐而不为呢?路漫漫其修远兮,吾将上下而求索。