基于数据窗口的统计函数设计
统计函数的概念
什么是统计函数,为什么需要统计函数?前面文章有讲过数据窗口的设计思路https://blog.junxworks.cn/articles/2018/10/30/1540871892864.html,数据窗口只是用于保存数据,保存数据用来做统计分析,如何做统计?统计函数就是用来对数据窗口中的数据做统计用的。统计函数在整个设计中,属于一个累计归纳的位置,数据窗口负责管理数据,统计函数则是从数据窗口提供的数据集合中归纳出统计值。由于部分数据窗口会涉及到累计这个动作,例如时间窗口,时间窗口是按切分块SlicedBlock做的累计,按道理时间窗口可以不用做数据累计,直接把每次交易的目标对象值保存就好,为啥要做累计呢?因为累计可以减少每个切分块中保存数据的大小,减少统计函数计算时候的计算量,从而减少计算时间,还可以减少网络传输的带宽,因此类似时间窗口这种有切分块功能的数据窗口,还需要统计函数提供一个切分块累计的功能,但是这个功能不会包含在函数主体,而是由函数另外提供类去实现。
综上所述,统计函数目前主要提供两个功能,累计和归纳。累计什么数据、归纳什么集合,均由数据窗口提供,统计函数不会做任何业务逻辑上的判断。
拿时间窗口的切分举例,每个切分块的管理是由时间窗口管理的,产生、过期和执行累计操作。但是具体怎么样去累计数据,这个交给统计函数自己去实现,例如求和的sum函数,有自己的SumSlicedBlock,这个是负责block累计的,Sum函数自身则实现对所有block的归纳。每个函数对SlicedBlock的累计方式不一样,根据函数自身决定,比如sum函数,则每个SlicedBlock只负责对数据进行求和累计,而唯一计数的SlicedBlock则记录去除重复后的统计目标值。
统计函数接口设计
统计函数最主要的功能就是根据给定数据集合,计算出结果值,至于这个数据集合是如何提供的,统计函数不用管。但是数据集合的累计功能,一定要根据统计函数提供的切分块去累计。统计函数对象本身主要实现归纳操作,因此主要接口只有一个,参考https://github.com/junxworks/junx/blob/master/junx-stat/src/main/java/io/github/junxworks/junx/stat/function/Function.java:
public Object getValue(Collection<?> data, StatContext context) throws Exception;
public <T> T getValue(Class<T> clazz, Collection<?> data, StatContext context) throws Exception;
UML类结构
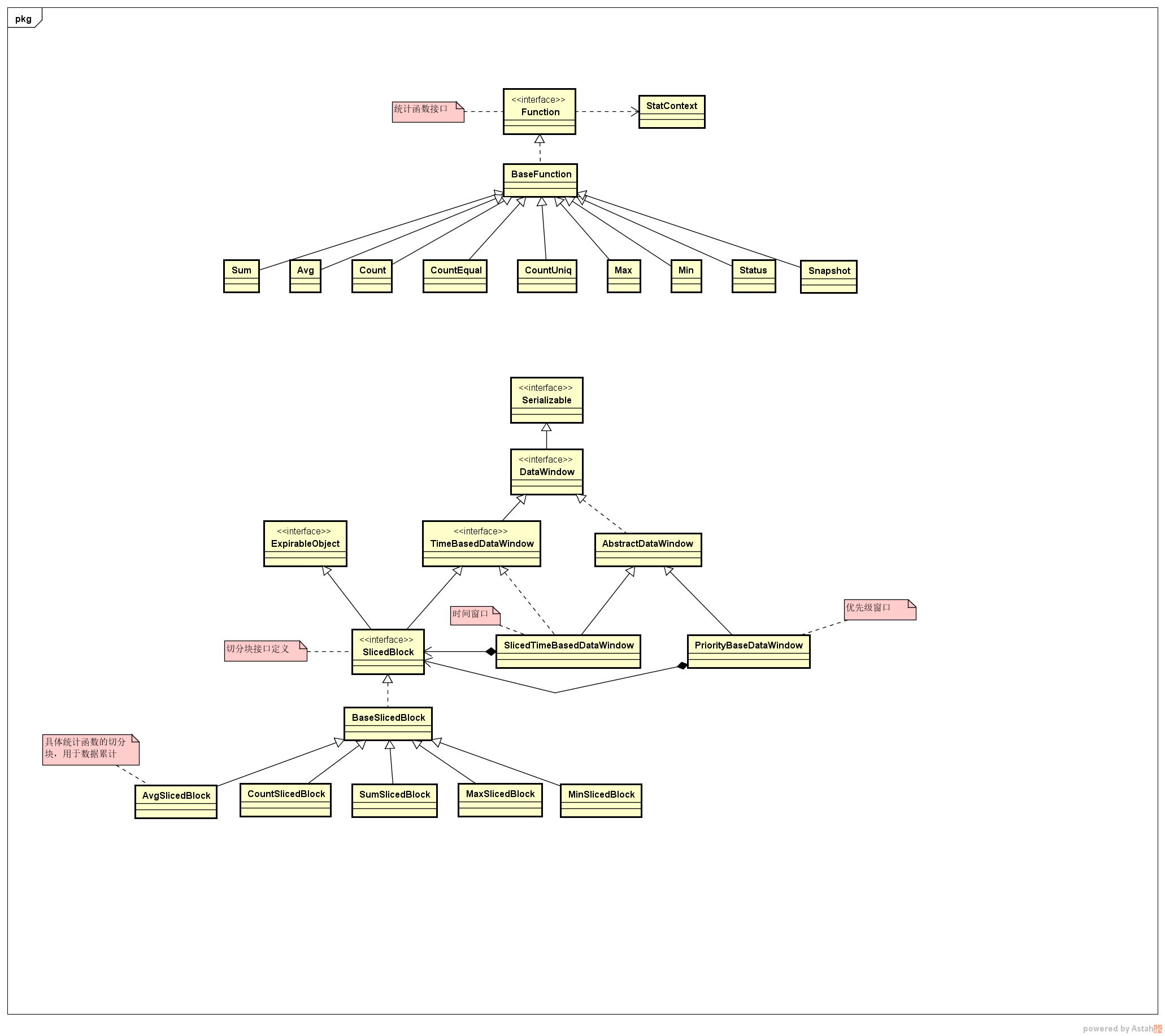
如上图所示,统计函数跟时间窗口是两条线,但是统计函数要负责切分块SlicedBlock的实现,Function接口的实现中,只负责具体算法逻辑的实现,可以参考sum函数的实现https://github.com/junxworks/junx/blob/master/junx-stat/src/main/java/io/github/junxworks/junx/stat/function/sum/Sum.java。统计函数的入参是一个数据集合,这个集合里面的数据组织,完全由函数自身去定义的,也就是通过切分块累计的方式,去定义函数内部数据集合的对象结构,因此固定的函数必须对应相同的切分块,例如sum函数只能对应sum的切分块,不能对应到其他函数的切分块,因为不同函数的切分块内部对象和数据格式可能不一样。
统计函数的切分块实现
上面UML中有很多函数的SlicedBlock,这个切分块是函数自身实现,提供给数据窗口使用的,主要用于数据累计,也就是根据函数自身算法,累计交易数据。不同的函数有不同的数据累计逻辑和数据格式,拿Min和Max函数举例,Min的SlicedBlock中,主要存历史数据和当前数据中较小的数据即可,而Max的SlicedBlock用于存放较大值,但是Min和Max只能用于数值类型的比较,而Snapshot函数可以用于存储字符串。具体实现可以参考https://github.com/junxworks/junx/blob/master/junx-stat/src/main/java/io/github/junxworks/junx/stat/function/max/MaxSlicedBlock.java和https://github.com/junxworks/junx/blob/master/junx-stat/src/main/java/io/github/junxworks/junx/stat/function/min/MinSlicedBlock.java。
切分块的序列化与反序列化
切分块本质上是java对象,可以采用java对象通用的序列化方式,例如JDK提供的java对象序列化方式、kryo的方式,直接把整个SlicedBlock序列化掉,但是没必要,因为格式是固定的,没必要将多余的数据序列化掉,因此这里只需要对本身的数据进行序列化即可,所以每个函数的数据格式、数据结构不同,每个函数由自身来定义序列化与反序列化的逻辑。junx-stat中的函数是使用ByteContainer来进行序列化与反序列化的,可以参考每个函数实现的SlicedBlock的toBytes与readBytes方法。例如sum函数https://github.com/junxworks/junx/blob/master/junx-stat/src/main/java/io/github/junxworks/junx/stat/function/sum/SumSlicedBlock.java。
总结
统计函数这块实现相对比较复杂,因为还要涉及到数据累计,序列化与反序列化,函数逻辑等功能,不过junx-stat已经实现了很多常用统计函数,可以参考其实现,github的地址为https://github.com/junxworks/junx/tree/master/junx-stat,并且提供了使用样例,参考https://github.com/junxworks/junx/tree/master/junx-sample/src/main/java/io/github/junxworks/junx/test/stat。