高并发下的跨进程并发控制
什么是并发控制?
在之前的文章里面,聊了一下什么是高并发https://blog.junxworks.cn/articles/2018/09/23/1537713102856.html,以及自己对高并发的理解,其中也简单的谈到了并发控制这个问题,其实并发控制概念上讲,不难理解,个人觉得并发控制就是在多个请求的环境下,控制请求或者任务的执行顺序,避免产生因为资源竞争导致的数据处理问题。跨进程的并发控制一直是高并发下的一个难题,解决这个问题的方式和手段有很多,但是感觉都不尽人意,下面聊一下并发控制这个老大难问题。
进程内并发控制
首先来说一下简单的,进程内的并发控制,方式和手段也有很多,这个相对于分布式的集群环境来说,简单很多。现在一提到进程内的并发控制,可能大多数人会想到锁,没错,锁是实现并发控制的最基本也最常用的一种方式,通过java的synchronized和Lock来实现多线程的并发控制是最常见的。其实另外还有一种方式,就是队列,这个得看应用程序内部是怎么设计的,在web应用中,前后台是同步应答的,这时候可能用锁的会多一点,如果是服务器端应用,例如基于SEDA并发架构的应用程序,那么可以把多线程下运算的业务,通过队列的方式,放到单线程中去做,这样做可能比多线程下通过锁竞争方式的效率更高,可以参考Disruptorhttp://ifeve.com/disruptor-getting-started/的做法。
进程内的并发控制,有非常非常多的资料来讲解了,这里就不围绕这个话题展开介绍了,有兴趣的可以自行百度。
跨进程并发控制
今天的主题是跨进程,这个难度比进程内的并发控制大多了,因为要考虑到性能瓶颈的问题,所以实现起来难度颇大。下面根据以往经验,聊一下跨进程的几种方式以及技术演进。
分布式锁
分布式锁是最常见的跨进程并发控制的方式,通过一个中间件,来控制请求的并发执行,不过这种方式功能相对薄弱,要进行更高级的控制,例如要根据请求的时序来进行先后控制,请求按时间先后顺序依次执行,分布式锁就显得有些无力。不过分布式锁实现起来比较简单,下面通过时序图的方式,来介绍一下分布式锁中悲观锁和乐观锁的实现。
悲观锁
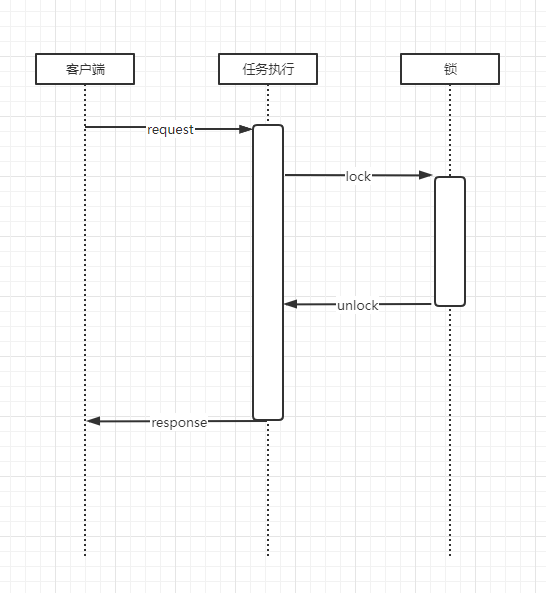
悲观锁的实现相对来说简单一点,在数据读取之前就获取锁,然后修改变更,最后提交修改释放锁,整个过程跟进程内的锁逻辑差不多,只是这个锁采用的是分布式锁。悲观锁整个锁的持有时间长,适合控制粒度细的控制,例如数据库中常用的行锁,如果是控制粒度大,则会导致大量请求排队。
乐观锁
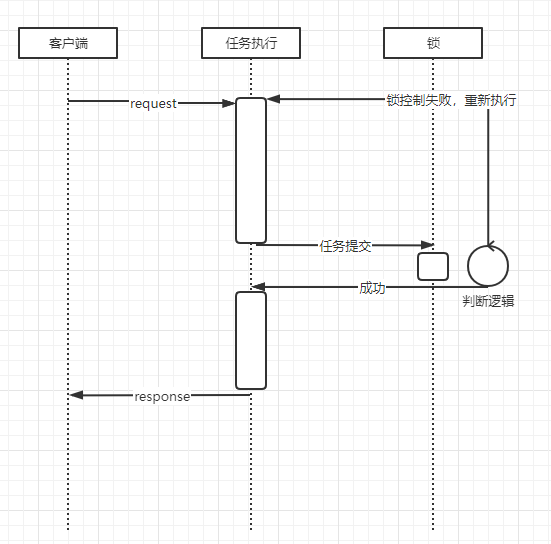
乐观锁的实现相对悲观锁来说,要复杂一点,从时序图上可以看到,乐观锁的锁持有时间很短,只在提交阶段才会去持有锁,但是在提交阶段需要进行逻辑判断,来验证在此期间,是不是发生过数据变更,如果是,则需要重新获取数据进行一次逻辑处理,再提交。乐观锁的逻辑验证,一般可以通过版本控制来进行验证,例如逻辑处理前,先查询一下最新的锁版本号,提交的时候验证一下当前版本号是不是之前获取的版本号,如果是则提交成功,如果不是则进行重试。综上所述,乐观锁适合并发修改小的场景,有助于提高系统的并发处理能力,如果大量并发修改导致retry次数过多,反而不如悲观锁来得划算。
总结
分布式锁的实现方式很多,例如目前开源的分布式协同工具zookeeper、数据库自带的锁、IMDG类的hazelcast和apache ignite都可以用来做分布式锁。分布式锁总体来说适合并发没有太高的场景,如果并发太高的话,锁这块会成为整个系统的性能瓶颈,而且不太容易处理这个问题,可能会涉及到整个系统的架构设计调整,因此对于并发高的业务场景,可以考虑其他的方式来实现跨进程的并发控制。
分布式队列
上面有说到分布式锁,这种方式适合并发不那么高的应用场景,如果说系统对响应时间这块要求非常高,那么就得对整个系统做架构调整,非常麻烦。因此我们可以采用分布式队列的方式,合理的规避资源竞争的问题,这也是我们之前做产品的时候总结出的一套比较合理的跨进程并发控制的方式。介绍分布式队列之前,先了解一个术语,对理解这种机制有帮助,这个术语就是一致性哈希。
一致性哈希
一致性哈希是一种哈希算法,它能够求出一个key对应的伪随机序列,这个序列恒久不变,可以用来做请求的节点分配算法。画了一个大概的一致性哈希的原理图,如下所示:
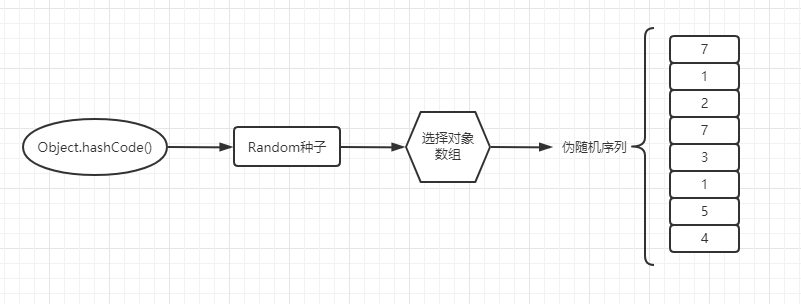
之前有写过一致性哈希算法的代码,很简单,可以在github上找到源码,参见https://github.com/junxworks/junx/tree/master/junx-core/src/main/java/io/github/junxworks/junx/core/chooser,chooser策略中的ConsistentHashingStrategy就是实现了一致性哈希算法的策略,另外可以参考chooser算法的测试样例ChooserTest.java。大致原理就是,根据一个对象的属性值,计算出对应的hashCode,根据hashCode生成一个Random对象,再通过这个Random对象+被选择的对象数组,生成一个伪随机序列,每个hashCode对应的伪随机序列是不变的,因此可以用来做请求分发策略。
采用一致性hash算法的好处呢,就是能够将对应请求平均的分发到每个服务器节点,并且自带failover策略,当一个服务器节点宕机时,这个服务器节点的所有请求会均匀的分配到剩余的服务器节点。
分布式队列的实现
基于一致性哈希这种选择算法,我们可以将有数据冲突的这类请求,根据一定的业务规则,发往同一个服务器进行处理,这个是分布式队列的必要条件,一定是将有资源竞争的请求发往同一个服务器节点。其次,再做好服务器内部的多线程并发控制。
1.0
1.0版本的分布式任务队列的实现如下图所示:
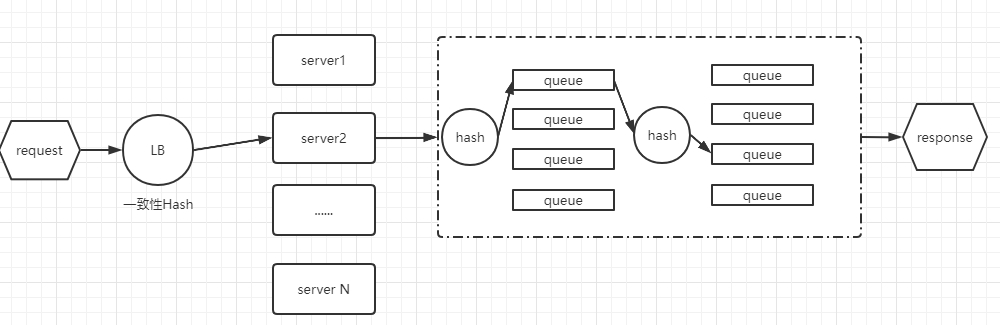
大致处理逻辑是,先将request通过一致性哈希算法,分配到具体的某个server节点,节点接受到请求后,再根据关键属性,将请求分配到某个具体的任务队列,每个队列后面跟着一个执行线程,由单线程来执行请求,如果server内部是基于SEDA并发结构来设计的,那么多个stage流转之间,还要再进行一次hash计算。这种思路就是将请求分配到固定的服务器中,固定的线程上去执行。好处就是没有分布式锁带来的性能瓶颈。当然有不足的地方,那就是服务器节点和线程队列数始终是有限的,这样N个不相关的request会被分配到同一个服务器的同一个任务队列,单线程去执行,如果某个请求耗时耽搁了,那么会导致整个任务队列堵塞,这也是1.0版本的不足之处。但是这种架构设计,让系统性能有了质的提升。
1.1
1.1版本的演进,相当于对1.0版本做了优化,大致实现原理如下图所示:
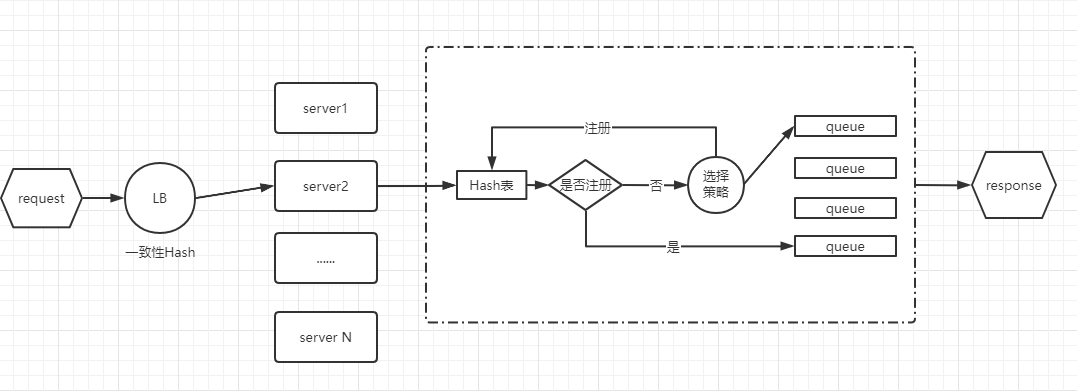
1.1版本跟1.0版本区别不大,主要在服务器内部执行的时候做了线程分配的优化,请求到来的时候可以根据策略,选择合适的线程来执行任务,并且在注册表中注册一下当前执行线程,任务执行完后从注册表中注销。下一次请求来的时候,先查询注册表中是否有对应的注册线程,有则分配到对应的线程,没有则根据策略选择合适的线程执行。这么做的好处就是,不用强制将所有不相关的任务都分配到同一个线程队列中去执行,如果某个线程发生了阻塞,可以根据选择策略,选择其他合适的线程执行。
2.0
1.1版本中,还是可能会发生不相关的请求之间,相互影响的现象,而且这么实现,让服务器内部逻辑复杂了很多,而且每个服务器节点是有状态的,对于服务器节点扩展来说,不太友好。因此2.0版本出来了,2.0版本中,将服务器的状态提取出来,单独处理,服务器只需安心处理业务即可,排队什么的,都交给外部网关来搞,大致原理图如下:
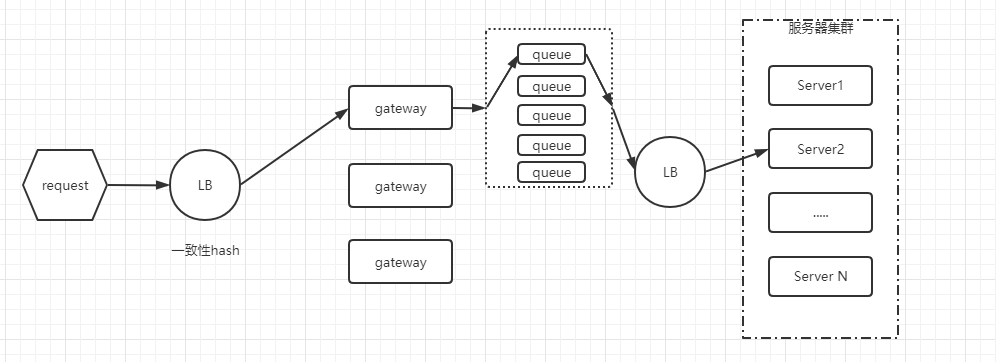
2.0版本做的最大改动是,将业务server内部的状态外置,提取出来做一个网关应用,request排队与后端服务器路由、负载均衡均在网关上实现,这么做的好处是将复杂逻辑从业务服务器抽离,解放业务服务器,网关上只做单一的工作,那就是任务的排队与服务器路由,任务排队可以将不同的请求分开排,这样解决了不同请求之间的干扰,另外将request和线程绑定这个问题解决掉,同时将request和后端server的紧耦合的问题也处理掉,业务服务器在当前版本是无状态的,只要保证网关无压力,业务服务器可以任意横向扩展。同时网关还可以复用,当有其他业务需要接入时,可以很方便的集成进来,不用再去管之前1.x版本的服务器内部实现。
总结
上面聊了一下自己对跨进程并发控制这块的理解和经验,本人才疏学浅,很多地方还没有理解透彻,希望能人多多点评和指导。